跳至内容
 在过去的十年里,英伟达一直在将自己从一个组件供应商转变为一个完整的平台供应商。这样的举动是没有必要的,但这与流行的想法是一致的,因为摩尔定律正在放慢,因此我们需要为堆栈的每个部分进行共同设计和共同优化,以发挥系统的最大性能。
没有计算、网络和存储在一起的系统是不存在的——这是一种高度依赖的三位一体。因此,任何平台玩家都不可避免地最终想要控制他们构建的系统的所有三个方面,并在越来越深的层面上控制它们。任何平台构建者都不可避免地想要控制那些密切关注计算、网络和存储的控制器。
Nvidia 联合创始人兼首席执行官Jensen Huang 也非常清楚这一点,这也是他将 GPU 制造商视为一家平台公司的原因。并在 2020 年 4 月收购 Mellanox Technologies 后接受我们采访时,他也表示了同样的观点。在业已宣告失败的Arm收购上同样如此。Nvidia 不需要 Arm 来充当一个更广泛计算的角色,它只需要一个 CPU,因此我们有理由相信明年推出的基于 Arm 的“Grace”CPU 将像Nvidia 的 GPU 计算引擎一样具有创新性。
在控制方面,英伟达在 AI Enterprise 下开发了自己的 Base Command 数据准备和机器学习训练运行管理软件,这是一个进行机器学习训练然后创建推理模型的工作流程;它还创建了 Fleet Command 编排和系统管理工具,用于在边缘运行 AI 的Enterprise。今年早些时候,英伟达支付了一笔未公开的金额来获得 BrightComputing,以便将其 Bright Cluster Manager 编入英伟达堆栈。
我们当时表示,如果 Nvidia 选择了 GigaIO 或 Liqid 等可组合和分解互连结构的几家制造商之一,我们不会感到惊讶,坦率地说,我们认为 Nvidia 将从那里开始,因为以灵活的方式分配 GPU 是一种对于很多客户来说,真正的问题是,提高这些昂贵的计算设备的效率也是如此。
NVM-Express 闪存也是如此,它正在被分解和动态组合以提高效率和性能,但方式略有不同。
这可能确实是 Nvidia 计划的一部分,但是昨日,随着 Excelero 的收购,Excelero 是过去几年一直在推动可分解和可组合存储的几家 NVM-Express 闪存初创公司之一,它开始看起来像 Nvidia 想要的那样。控制其自己的用于 HPC 和 AI 应用程序的块存储,并将组成它以在其以太网和可能的 InfiniBand 网络上运行,并且很可能使用基于 Connect-X NIC、BlueField 多核 Arm 处理器和 Nvidia GPU 组合的 DPU,并且可能在原始 BlueField CPU 充当存储节点控制器,而不是 X86 处理器。后一点是我们看到 Mellanox 在 2019 年的开放计算峰会上玩弄的东西,它的 SNAP 是Software-definedNetwork Accelerated Processing的缩写。
为了向 Nvidia 堆栈添加存储,Nvidia 可以在 Twitter 收购DriveScale之前收购它,甚至可以收购Lightbits Labs,这是另一个使用 NVM-Express over Fabrics 来集群存储的有趣供应商。但相反,Nvidia 选择了收购 Excelero。
Excelero 于 2014 年在以色列特拉维夫成立,随后将其总部迁至圣何塞,靠近英伟达、英特尔和其他IT 巨头。Lior Gal 多年来一直在 DataDirect Networks 负责其内容和媒体业务的销售,他是公司联合创始人,并担任了多年的首席执行官。Yaniv Romem 曾任服务器管理程序制造商 ScaleMP 研发副总裁,是该公司原首席技术官,并继 Gal 之后担任 CEO。OferOshri 也是 ScaleMP 的核心团队负责人,他仍然是研发副总裁,而 Omri Mann 仍然是首席科学家,他显然创建了世界上第一个防病毒软件并曾在ScaleMP 任职。在 EMC 斥资 4.3 亿美元收购闪存创新者XtremIO 之前,KirillShoiket领导了 XtremIO 的最终架构,然后被 Excelero 聘为首席技术官。Excelero 在退出隐身之前和之后不久筹集了四轮资金,并在 2018 年 8 月之前筹集了3500 万美元。Battery Ventures、SquarePeg Capital、Qualcomm Ventures 和Western Digital Ventures 以及一些个人投资者都投入了资金。
Mellanox 以及现在的 Nvidia 也是Excelero 的投资者。考虑到过去四年里有很多现金四处游荡,这金额其实并不算高。
NVMesh 的有趣之处在于,虽然它是分布式块存储,可以运行文件并行系统,如 Lustre、SpectrumScale (GPFS) 或 BeeGFS,用作传统 HPC 仿真和建模应用程序的暂存器存储,但对于非结构化和使用机器学习训练神经网络所需的半结构化数据,可以通过让集群中的本地节点从节点上运行的任何文件系统(通常是 XFS)安装 NVMesh 来避免并行文件系统的这种开销,给人一种并行文件系统的感觉,没有任何麻烦。
NVMesh 可以在许多不同的协议和结构上运行——普通的 TCP/IP、NVM-Express over Fabrics、InfiniBand 或带有 RoCE v2 的以太网——以访问网络上的闪存存储并使所有内容看起来对集群中的所有节点都是本地的。Excelero提出的秘诀称为远程直接驱动器访问 (RDDA:Remote Direct Drive Access) 协议,它是一种直接与节点中的NVM-Express 闪存设备通信而无需访问 CPU 上的驱动程序的方法。就像 InfiniBand RDMA 和以太网 RoCE 允许两个网卡相互聊天并访问 CPU 或 GPU 主内存,而无需通过CPU 驱动程序堆栈,或者 NVM-Express 允许CPU 访问闪存而无需通过 PCI-Express 驱动程序并使用访问闪存的 SCSI 协议。RDDA 协议已获得专利,与在节点中本地访问相比,通过网络访问远程闪存仅增加 5 微秒的延迟开销。
NVMesh 存储软件可以在带有闪存的标准服务器上运行,也可以在基于闪存的实例上的公共云上运行,以创建虚拟闪存阵列。而且,对于 Nvidia 来说重要的是,Excelero 堆栈已经过调整,可以与 Nvidia 的 Magnum IO 存储加速软件层一起工作。
您可能会认为,鉴于驱动机器学习训练的非结构化数据量,系统上的对象存储量与块存储量相比会大得多。但是如果你看一下研究超级计算机 (RSC) 系统的 760 节点第一阶段,Pure Storage 提供了175 PB 的 FlashArray 块存储,但只有 10PB 的 FlashBlade 对象存储;还有一个 46 PB的“缓存集群”位于架构中的某个位置,我们强烈怀疑这是基于磁盘的数据集存档,而不是生产存储。主存储的容量将增长到超过 1 艾字节,而 Nvidia 无疑看到了这笔交易中 Pure Storage 的收入——富国银行分析师 Aaron Rakers 估计 RSC 的存储将为 Pure Storage 的金库贡献 3000 万美元.
当我们写这篇文章时,我们还没有意识到Nvidia 上周晚些时候收购了 SwiftStack,并在此评论说,如果 Nvidia 决定它也需要对象存储来完成 AI 和 HPC 的存储软件集,我们不会感到惊讶。我们建议 MinIO 是一个显而易见的选择,Ceph 由 Red Hat 控制,因此由 IBM 控制。当然,Ceph 也是一种选择,还有许多其他对象存储选择(包括实际收购的 SwiftStack)。Mellanox 还持有 WekaIO 的股份,如果 Nvidia 认为它需要一个并行文件系统,该系统对 HPC 和 AI 工作负载非常有效,那么收购这家公司也可能大放异彩。这将在很大程度上完善数据中心的存储版图,也将是最后一块。
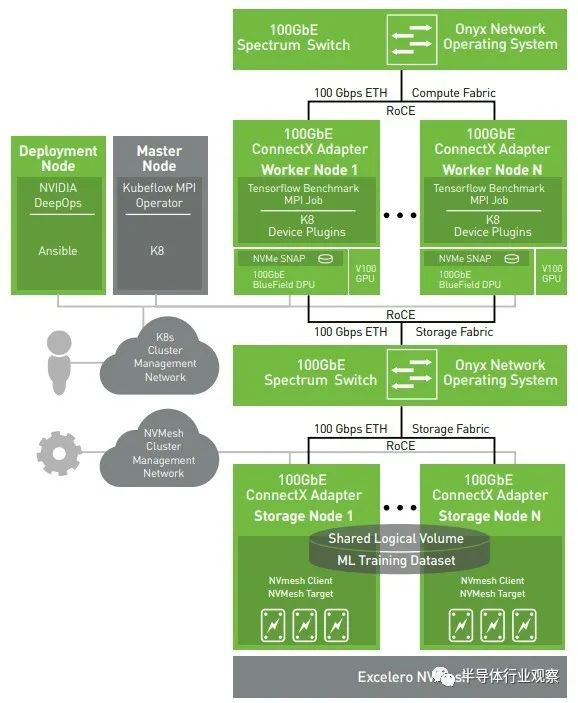
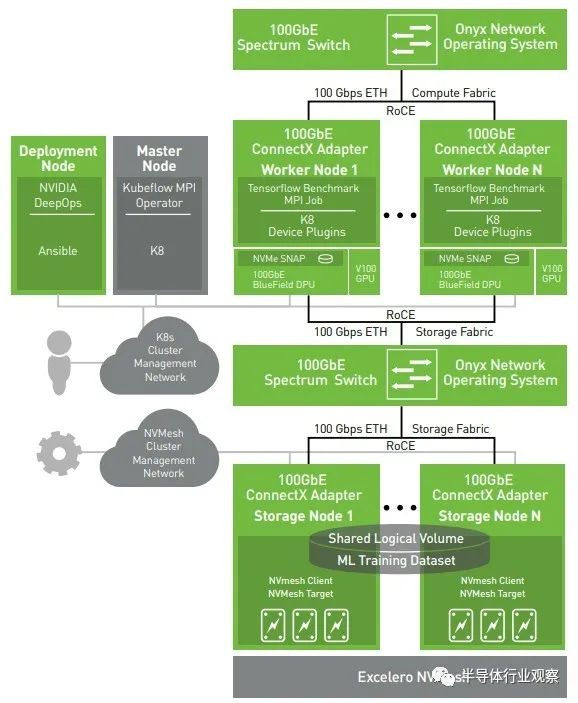
Nvidia 收购 Excelero 不仅是为了赚钱,也是为了更好地共同设计完整的 Nvidia HPC 和 AI 堆栈。Nvidia硬件和软件与 Excelero NVMesh 的很多集成已经完成,您可以在此处看到:
正如我们之前指出的,每个存储节点上的存储控制器没有理由必须是 X86 服务器。只要有足够的 PCI-Express 通道连接到 NVM-Express 闪存,BlueField 驱动的 DPU 就可以解决问题。在最长的运行中,Nvidia 可以使用 Grace Arm 服务器 CPU 作为存储节点控制器,如果它需要更多的功能。关键是 Nvidia 拥有更多的堆栈,并增加其代工合作伙伴蚀刻的芯片的数量。
在过去的十年里,英伟达一直在将自己从一个组件供应商转变为一个完整的平台供应商。这样的举动是没有必要的,但这与流行的想法是一致的,因为摩尔定律正在放慢,因此我们需要为堆栈的每个部分进行共同设计和共同优化,以发挥系统的最大性能。
没有计算、网络和存储在一起的系统是不存在的——这是一种高度依赖的三位一体。因此,任何平台玩家都不可避免地最终想要控制他们构建的系统的所有三个方面,并在越来越深的层面上控制它们。任何平台构建者都不可避免地想要控制那些密切关注计算、网络和存储的控制器。
Nvidia 联合创始人兼首席执行官Jensen Huang 也非常清楚这一点,这也是他将 GPU 制造商视为一家平台公司的原因。并在 2020 年 4 月收购 Mellanox Technologies 后接受我们采访时,他也表示了同样的观点。在业已宣告失败的Arm收购上同样如此。Nvidia 不需要 Arm 来充当一个更广泛计算的角色,它只需要一个 CPU,因此我们有理由相信明年推出的基于 Arm 的“Grace”CPU 将像Nvidia 的 GPU 计算引擎一样具有创新性。
在控制方面,英伟达在 AI Enterprise 下开发了自己的 Base Command 数据准备和机器学习训练运行管理软件,这是一个进行机器学习训练然后创建推理模型的工作流程;它还创建了 Fleet Command 编排和系统管理工具,用于在边缘运行 AI 的Enterprise。今年早些时候,英伟达支付了一笔未公开的金额来获得 BrightComputing,以便将其 Bright Cluster Manager 编入英伟达堆栈。
我们当时表示,如果 Nvidia 选择了 GigaIO 或 Liqid 等可组合和分解互连结构的几家制造商之一,我们不会感到惊讶,坦率地说,我们认为 Nvidia 将从那里开始,因为以灵活的方式分配 GPU 是一种对于很多客户来说,真正的问题是,提高这些昂贵的计算设备的效率也是如此。
NVM-Express 闪存也是如此,它正在被分解和动态组合以提高效率和性能,但方式略有不同。
这可能确实是 Nvidia 计划的一部分,但是昨日,随着 Excelero 的收购,Excelero 是过去几年一直在推动可分解和可组合存储的几家 NVM-Express 闪存初创公司之一,它开始看起来像 Nvidia 想要的那样。控制其自己的用于 HPC 和 AI 应用程序的块存储,并将组成它以在其以太网和可能的 InfiniBand 网络上运行,并且很可能使用基于 Connect-X NIC、BlueField 多核 Arm 处理器和 Nvidia GPU 组合的 DPU,并且可能在原始 BlueField CPU 充当存储节点控制器,而不是 X86 处理器。后一点是我们看到 Mellanox 在 2019 年的开放计算峰会上玩弄的东西,它的 SNAP 是Software-definedNetwork Accelerated Processing的缩写。
为了向 Nvidia 堆栈添加存储,Nvidia 可以在 Twitter 收购DriveScale之前收购它,甚至可以收购Lightbits Labs,这是另一个使用 NVM-Express over Fabrics 来集群存储的有趣供应商。但相反,Nvidia 选择了收购 Excelero。
Excelero 于 2014 年在以色列特拉维夫成立,随后将其总部迁至圣何塞,靠近英伟达、英特尔和其他IT 巨头。Lior Gal 多年来一直在 DataDirect Networks 负责其内容和媒体业务的销售,他是公司联合创始人,并担任了多年的首席执行官。Yaniv Romem 曾任服务器管理程序制造商 ScaleMP 研发副总裁,是该公司原首席技术官,并继 Gal 之后担任 CEO。OferOshri 也是 ScaleMP 的核心团队负责人,他仍然是研发副总裁,而 Omri Mann 仍然是首席科学家,他显然创建了世界上第一个防病毒软件并曾在ScaleMP 任职。在 EMC 斥资 4.3 亿美元收购闪存创新者XtremIO 之前,KirillShoiket领导了 XtremIO 的最终架构,然后被 Excelero 聘为首席技术官。Excelero 在退出隐身之前和之后不久筹集了四轮资金,并在 2018 年 8 月之前筹集了3500 万美元。Battery Ventures、SquarePeg Capital、Qualcomm Ventures 和Western Digital Ventures 以及一些个人投资者都投入了资金。
Mellanox 以及现在的 Nvidia 也是Excelero 的投资者。考虑到过去四年里有很多现金四处游荡,这金额其实并不算高。
NVMesh 的有趣之处在于,虽然它是分布式块存储,可以运行文件并行系统,如 Lustre、SpectrumScale (GPFS) 或 BeeGFS,用作传统 HPC 仿真和建模应用程序的暂存器存储,但对于非结构化和使用机器学习训练神经网络所需的半结构化数据,可以通过让集群中的本地节点从节点上运行的任何文件系统(通常是 XFS)安装 NVMesh 来避免并行文件系统的这种开销,给人一种并行文件系统的感觉,没有任何麻烦。
NVMesh 可以在许多不同的协议和结构上运行——普通的 TCP/IP、NVM-Express over Fabrics、InfiniBand 或带有 RoCE v2 的以太网——以访问网络上的闪存存储并使所有内容看起来对集群中的所有节点都是本地的。Excelero提出的秘诀称为远程直接驱动器访问 (RDDA:Remote Direct Drive Access) 协议,它是一种直接与节点中的NVM-Express 闪存设备通信而无需访问 CPU 上的驱动程序的方法。就像 InfiniBand RDMA 和以太网 RoCE 允许两个网卡相互聊天并访问 CPU 或 GPU 主内存,而无需通过CPU 驱动程序堆栈,或者 NVM-Express 允许CPU 访问闪存而无需通过 PCI-Express 驱动程序并使用访问闪存的 SCSI 协议。RDDA 协议已获得专利,与在节点中本地访问相比,通过网络访问远程闪存仅增加 5 微秒的延迟开销。
NVMesh 存储软件可以在带有闪存的标准服务器上运行,也可以在基于闪存的实例上的公共云上运行,以创建虚拟闪存阵列。而且,对于 Nvidia 来说重要的是,Excelero 堆栈已经过调整,可以与 Nvidia 的 Magnum IO 存储加速软件层一起工作。
您可能会认为,鉴于驱动机器学习训练的非结构化数据量,系统上的对象存储量与块存储量相比会大得多。但是如果你看一下研究超级计算机 (RSC) 系统的 760 节点第一阶段,Pure Storage 提供了175 PB 的 FlashArray 块存储,但只有 10PB 的 FlashBlade 对象存储;还有一个 46 PB的“缓存集群”位于架构中的某个位置,我们强烈怀疑这是基于磁盘的数据集存档,而不是生产存储。主存储的容量将增长到超过 1 艾字节,而 Nvidia 无疑看到了这笔交易中 Pure Storage 的收入——富国银行分析师 Aaron Rakers 估计 RSC 的存储将为 Pure Storage 的金库贡献 3000 万美元.
当我们写这篇文章时,我们还没有意识到Nvidia 上周晚些时候收购了 SwiftStack,并在此评论说,如果 Nvidia 决定它也需要对象存储来完成 AI 和 HPC 的存储软件集,我们不会感到惊讶。我们建议 MinIO 是一个显而易见的选择,Ceph 由 Red Hat 控制,因此由 IBM 控制。当然,Ceph 也是一种选择,还有许多其他对象存储选择(包括实际收购的 SwiftStack)。Mellanox 还持有 WekaIO 的股份,如果 Nvidia 认为它需要一个并行文件系统,该系统对 HPC 和 AI 工作负载非常有效,那么收购这家公司也可能大放异彩。这将在很大程度上完善数据中心的存储版图,也将是最后一块。
Nvidia 收购 Excelero 不仅是为了赚钱,也是为了更好地共同设计完整的 Nvidia HPC 和 AI 堆栈。Nvidia硬件和软件与 Excelero NVMesh 的很多集成已经完成,您可以在此处看到:
正如我们之前指出的,每个存储节点上的存储控制器没有理由必须是 X86 服务器。只要有足够的 PCI-Express 通道连接到 NVM-Express 闪存,BlueField 驱动的 DPU 就可以解决问题。在最长的运行中,Nvidia 可以使用 Grace Arm 服务器 CPU 作为存储节点控制器,如果它需要更多的功能。关键是 Nvidia 拥有更多的堆栈,并增加其代工合作伙伴蚀刻的芯片的数量。