
核心结论
1. 先进制程受限,先进封装/Chiplet提升算力,必有取舍。
在技术可获得的前提下,提升芯片性能,先进制程升级是首选,先进封装则锦上添花。
2. 大功耗、高算力的场景,先进封装/Chiplet有应用价值。
3. 我国先进制程产能储备极少,先进封装/Chiplet有助于弥补制程的稀缺性。
先进封装/Chiplet可以释放一部分先进制程产能,使之用于更有急迫需求的场景。 用面积和堆叠跨越摩尔定律限制 芯片升级的两个永恒主题:性能、体积/面积。芯片技术的发展,推动着芯片朝着高性能和轻薄化两个方向提升。而先进制程和先进封装的进步,均能够使得芯片向着高性能和轻薄化前进。面对美国的技术封装,华为难以在全球化的先进制程中分一杯羹,手机、HPC等需要先进制程的芯片供应受到严重阻碍,亟需另辟蹊径。而先进封装/Chiplet等技术,能够一定程度弥补先进制程的缺失,用面积和堆叠换取算力和性能。
01 先进制程受限,先进封装/Chiplet
提升算力,必有取舍
何谓先进封装?
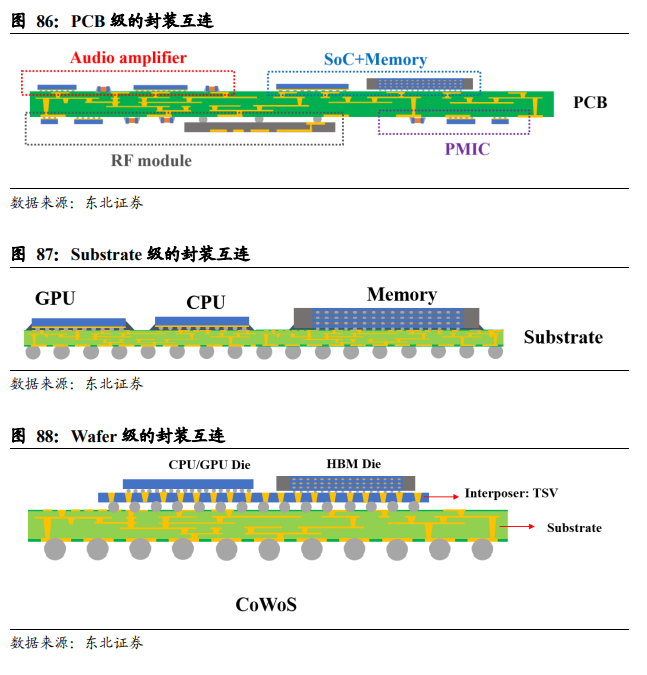
先进封装是对应于先进圆晶制程而衍生出来的概念,一般指将不同系统集成到同一封装内以实现更高效系统效率的封装技术。换言之,只要该封装技术能够实现芯片整体性能(包括传输速度、运算速度等)的提升,就可以视为是先进封装。传统的封装是将各个芯片单独封装好,再将这些单独的封装芯片装配到PCB主板上构成完整的系统,芯片间的信息交换属于PCB级的互连(interconnect),又称板级互连;或者将不同的芯片贴装到同一个封装基板Substrate上,再完成系统级的封装,芯片间的通讯属于Substrate级的互连。这两种形式的封装互连技术,芯片间的信息传输需要通过PCB或Substrate布线完成。理论上,芯片间的信息传输距离越长,信息传递越慢,芯片组系统的性能就越低。因此,同一芯片水平下,PCB级互连的整体性能比Substrate级互连的性能弱。
在摩尔定律失效之前,芯片系统性能的提升可以完全依赖于芯片本身制程提升(制程提升使得芯片集成晶体管数量提升)。但随着摩尔定律失效,芯片制程提升速度大大放缓,芯片系统性能的提升只能通过不断优化各个芯片间的信息传输效率,圆晶Wafer级封装互连技术的价值凸显。 Wafer级的封装互连技术,将不同的SoC集成在TSV(硅通孔技术:Through silicon via)内插板(interposer)上。Interposer本身材料为硅,与SoC的衬底硅片相同,通过TSV技术以及再布线(RDL)技术,实现不同SoC之间的信息交换。换言之,SoC之间的信息传输是通过Interposer完成。
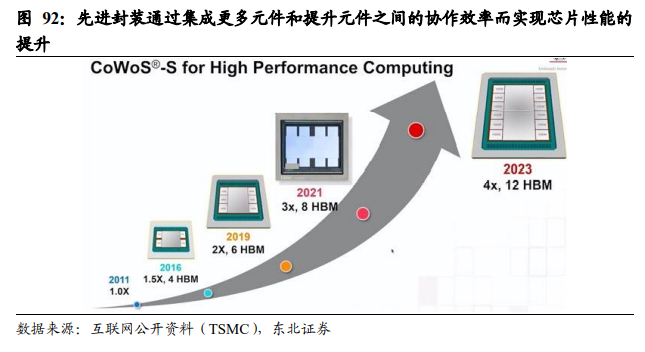
Interposer再布线采用圆晶光刻工艺,比PCB和Substrate布线更密集,线路距离更短,信息交换更快,因此可以实现芯片组整体性能的提升。图XX示例为CoWoS封装(Chip on Wafer on Substrate),CPU/GPU die与Memory die通过interposer实现互连,信息直接通过interposer上的RDL布线传输,不经过Substrate或PCB,信息交换快,系统效率高。 从半导体制程进入10nm以来,摩尔定律已经失效,即芯片迭代不再满足“集成电路芯片上所集成的晶体管数目,每隔18个月就翻一番;微处理器的性能每隔18个月提高一倍,而价格下降一倍”。在后摩尔定律时代,对于“more than moore”的延续,先进封装是业界公认的有效途径。
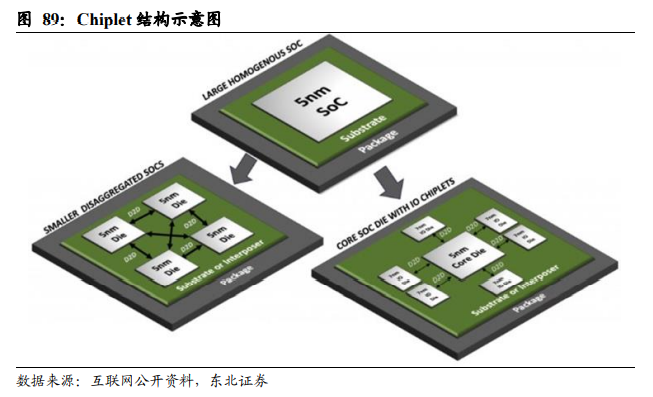
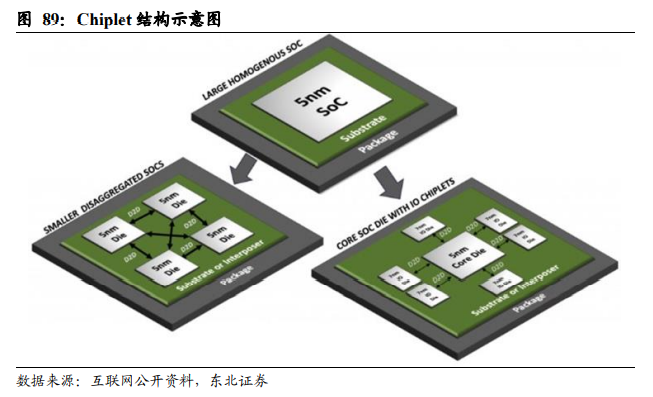
何谓Chiplet?
Chiplet即小芯片之意,指在晶圆端将原本一颗“大”芯片(Die)拆解成几个“小”芯片(Die),因单个拆解后的“小”芯片在功能上是不完整的,需通过封装,重新将各个“小”芯片组合起来,功能上还原原来“大”芯片的功能。Chiplet可以将一颗大芯片拆解设计成几颗与之有相同制程的小芯片,也可以将其拆解成设计成几颗拥有不同制程的小芯片。
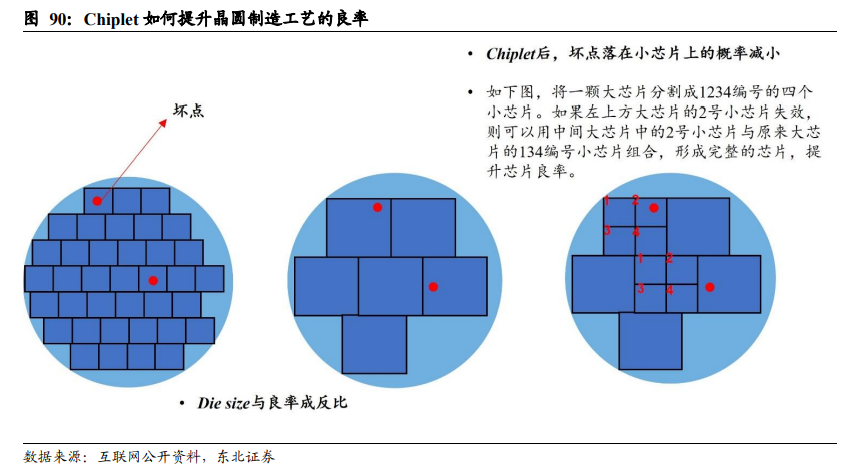
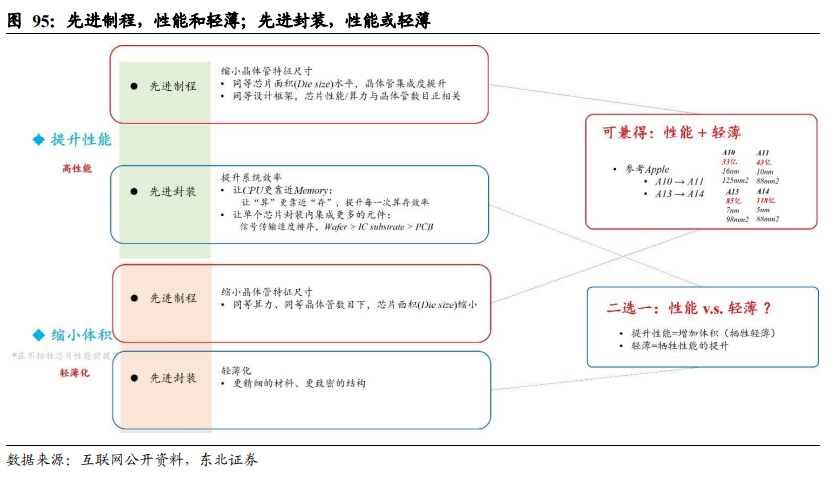
Chiplet可以提升芯片制造的良率。对于晶圆制造工艺而言,芯片面积(Die size)越大,工艺的良率越低。可以理解为,每片wafer上都有一定概率的失效点,对于晶圆工艺来说,在同等技术条件下难以降低失效点的数量,如果被制造的芯片,其面积较大,那么失效点落在单个芯片上的概率就越大,因而良率就越低。如果Chiplet的手段,将大芯片拆解分割成几颗小芯片,单个芯片面积变小,失效点落在单个小芯片上的概率将大大降低。芯片面积Die size与良率成反比。(注:以上解读仅为东北电子团队调研学习理解后的观点,不具备业界技术权威性,仅供投资者理解基础概念用) 先进制程和先进封装,对芯片性能、轻薄化的提升,孰更显著? 在提升芯片性能方面,先进制程路线是通过缩小单个晶体管特征尺寸,在同等芯片面积(Die size)水平下,提升晶体管集成度(同等设计框架,芯片性能/算力与晶体管数目正相关);而先进封装并不能改变单个晶体管尺寸,只能从系统效率提升的角度,一是让CPU更靠近Memory,让“算”更靠近“存”,提升每一次计算的算存效率。二是让单个芯片封装内集成更多的元件:信号传输速度排序,Wafer > IC substrate > PCB,元件在芯片内部的通讯效率比在板级上更高,从系统层面提升芯片性能。
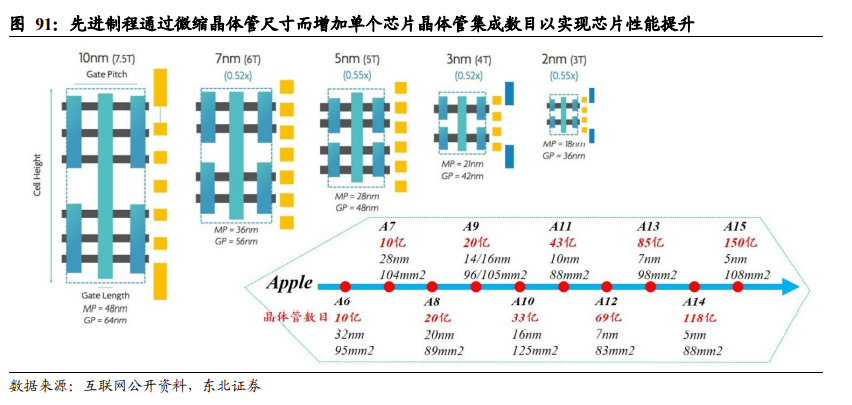
在芯片轻薄化方面,在不牺牲芯片整体性能的前提下,先进制程能够在算力和晶体管数目不变时,通过缩小单个晶体管特征尺寸,实现芯片面积(Die size)缩小;而先进封装,因为封装对晶体管尺寸无微缩的能力,只能通过更精细的材料、更致密的结构来实现轻薄化。比如,手机AP处理器的封装多采用FCCSP的封装形式,其结构包括一个CSP载板,而Fanout(TSMC与APPLE公司合作,APPLE公司的A系列芯片多采用InFO技术封装,即Fannout)封装,取消了CSP载板(CSP载板约0.3 mm厚度),封装后的芯片更轻薄,对整机(手机)结构空间余量有重要提升。

在高性能和轻薄化两个方向上,先进制程可以做到兼顾,而先进封装则有取舍。比如,APPLE的A系列芯片,从A10升级到A11时,由16 nm工艺提升至10 nm工艺,芯片面积从125 mm2减小至88 mm2,而晶体管集成数则由33亿颗增加至43亿颗;A系列芯片从A13升级到A14时,晶圆工艺从7nm升级到5nm,芯片面积从98 mm2减小至88 mm2,而晶体管集成数则由85亿颗增加至118亿颗,做到了性能提升和轻薄化的兼顾。而先进封装,要做到芯片性能提升,因为封装对晶体管尺寸微缩没有效果,提升性能一是增加芯片内部各元件的协作效率,二是往一个系统中堆叠更多的元件(本质上也是提升了系统内的晶体管数据),代价就是系统体积、面积更为庞大,即先进封装提升性能的代价是牺牲轻薄,实现轻薄的代价是牺牲性能的提升。
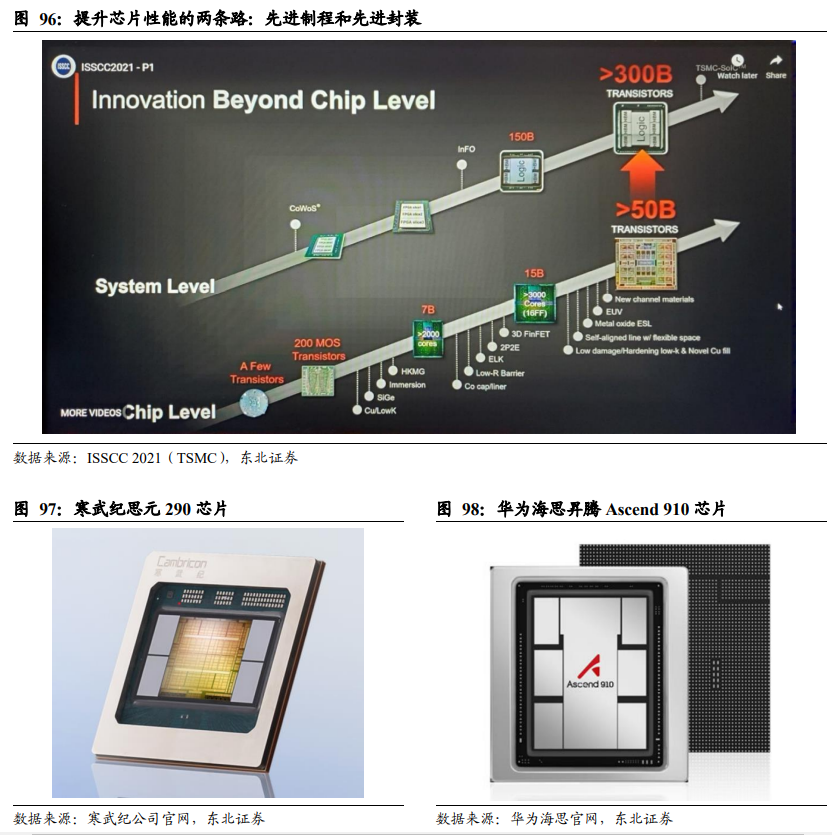
在技术可获得的前提下,提升芯片性能,先进制程升级是首选,先进封装则锦上添花。通常我们可以见到的是,高性能、大算力的芯片,会考虑上先进封装(2.5D、CoWoS等),但这些大算力芯片往往也同时采用的先进制程工艺,也就是说,先进封装/Chiplet应用通常只出现在顶级的旗舰芯片的封装方案选择中,并不是一个普适性的大规模应用方案。比如寒武纪的7 nm AI训练芯片思元290,从芯片宣传图片可以看出,其可能采用“1+4”架构,即1颗CPU/GPU搭配4颗HBM存储的Chiplet封装形式,该芯片也是寒武纪的旗舰芯片产品之一;华为海思昇腾910芯片,采用7 nm的先进制程工艺,从宣传图可以看出,也是采用了多颗芯片堆叠的CoWoS结构,也系Chiplet的一种形式。这些芯片都是在拥有先进制程的基础上,为了进一步提升芯片性能,而采用了CoWoS这些2.5D先进封装技术,说明了先进制程在工艺路线的选择上是优于先进封装的,先进制程是升级芯片性能的首选,先进封装则是锦上添花。
02 大功耗、高算力的场景,
先进封装/Chiplet有应用价值
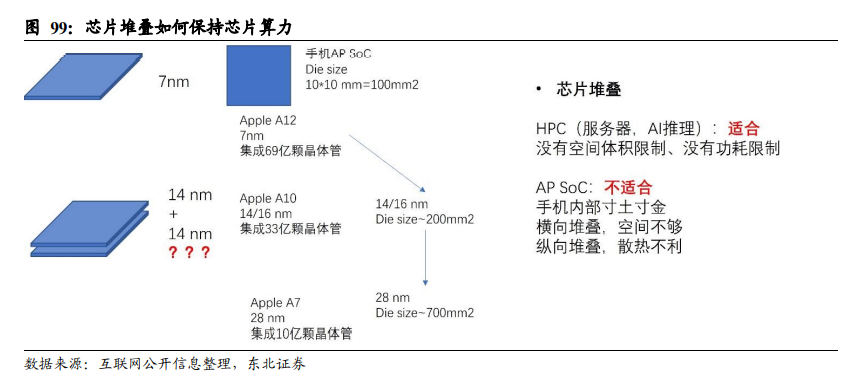
在先进制程不可获得的情况下,通过芯片堆叠(先进封转/Chiplet)和计算架构重构,以维持产品性能。以APPLE的A系列芯片参数为例,A12、A10、A7芯片分别采用7 nm、14/16 nm(Samsung 14 nm、TSMC 16 nm)、28 nm制程。A系列的手机AP芯片,通常芯片面积(Die Size)在约100 mm2大小。在这100 mm2大小的芯片上, A12、A10、A7芯片分别集成了约69亿、33亿、10亿颗晶体管。下面,我们简单进行算术换算,讨论降制程如何维持芯片的算力。如果芯片工艺从7 nm降至14 nm,A12芯片上7nm工艺集成69亿颗晶体管,如果用14 nm工艺以试图达到接近的算力,首先要保证晶体管数目与A12芯片一致,即~70亿颗,且在未考虑制程提升对单个晶体管性能有显著提升的背景下,14 nm工艺的芯片需要两倍于7 nm工艺的面积,即~200 mm2;如果芯片工艺从7 nm降至28 nm,参考28 nm的A7芯片只集成了10亿颗晶体管,如果要达到70亿晶体管数目,则需要将芯片面积扩大至~700 mm2。
芯片面积越大,工艺良率越低,在实际制造中得到的单颗芯片的制造成本就越高,因此,在先进制程不可获得的背景下,降制程而通过芯片堆叠的方式,的确可以一定程度减少算力劣势,但是因为堆叠更多芯片,需要更大的IC载板、更多的Chiplet小芯片、更多的封装材料,也导致因为制程落后带来的功耗增大、体积/面积增加、成本的增加。因此,比如,通过14 nm的两颗芯片堆叠,去达到同样晶体管数目的7 nm芯片性能;通过多颗28 nm的芯片堆叠,去达到14 nm芯片性能。此种堆叠方案在HPC(服务器、AI推理)、基站类大芯片领域可能有适用价值,但对于消费电子领域如手机AP芯片和可穿戴芯片,在其应用场景对空间体积有严苛约束的条件下,芯片堆叠则较难施展。
03 我国先进制程产能储备极少,先进
封装/Chiplet有助于弥补制程的稀缺性
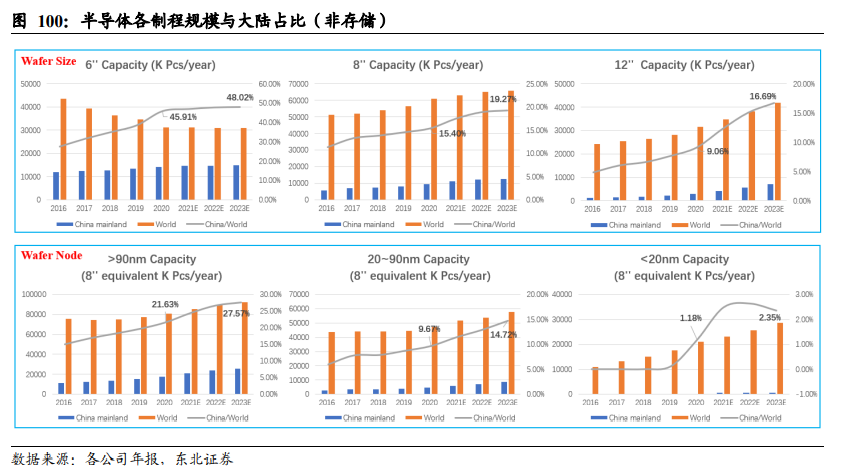
尖端科技全球化已死,大陆先进制程的产能极为稀缺、紧缺。按不同晶圆尺寸统计,大陆6英寸晶圆产能已占全球近一半,而12英寸产能仅为全球约10%。按不同制程统计,大陆90 nm以上制程占全球约20%,20-90 nm制程占全球约10%,20 nm以下制程仅占全球约1%。大陆高端制程占比低,产业结构存在明显短板,未来扩产空间大。高端制程扩产投入大,3 nm制程芯片每万片产能的投资约100亿美元,远高于28 nm制程芯片每万片约7亿美元的投资。弥补大陆晶圆产业结构短板,需重点投资高端制程晶圆制造产能,既需要完成技术攻关,又需要大额投资支持,任重而道远。
先进封装/Chiplet可以释放一部分先进制程产能,使之用于更有急迫需求的场景。从上文分析可见,通过降制程和芯片堆叠,在一些没有功耗限制和体积空间限制、芯片成本不敏感的场景,能够减少对先进制程的依赖。可以将当下有限的先进制程产能,以更高的战略视角,统一做好规划,应用在更需要先进工艺的应用需求中。
(文章来源:算力基建)
![]()