
自7多年前推出至今, CUDA 统一内存编程模型一直在开发人员中广受欢迎。统一内存为 GPU 应用程序的原型设计提供了一个简单的接口,而无需在主机和设备之间手动 MIG 评级内存。
从 NVIDIA Pascal 更容易扩展到更大的问题规模体系结构开始,支持统一内存的应用程序可以使用系统 CPU 中所有可用的 CPU 和 GPU 内存。有关使用统一内存开始 GPU 计算的更多信息,请参阅 CUDA 更简单的介绍。
您是否希望使用大型数据集无缝运行应用程序,同时保持内存管理简单?统一内存可用于使虚拟内存分配大于可用 GPU 内存。在发生超额订阅时, GPU 自动开始将内存页逐出到系统内存,以便为活动的在用虚拟内存地址腾出空间。
但是,应用程序性能在很大程度上取决于内存访问模式、数据驻留和运行的系统。在过去几年中,我们发表了几篇关于使用统一内存实现 GPU 内存超额订阅的文章。我们通过各种编程技术(如预取和内存使用提示)为您的应用程序实现更高的性能提供了帮助。
在这篇文章中,我们深入研究了一个微基准测试的性能特征,它强调了超额订阅场景中不同的内存访问模式。它可以帮助您分解并了解统一内存的所有性能方面:什么时候适合,什么时候不适合,以及您可以做些什么。正如您将从我们的结果中看到的,根据平台、超额订阅因素和内存提示,性能可能会变化 100 倍。我们希望这篇文章能让您更清楚地知道何时以及如何在应用程序中使用统一内存!
基准设置和访问模式
要评估统一内存超额订阅性能,可以使用分配和读取内存的简单程序。使用cudaMallocManaged分配一大块连续内存,然后在 GPU 上访问该内存,并测量有效的内核内存带宽。不同的统一内存性能提示,如cudaMemPrefetchAsync和cudaMemAdvise修改分配的统一内存。我们将在本文后面讨论它们对性能的影响。
我们定义了一个名为“ oversubscription factor ”的参数,它控制分配给测试的可用 GPU 内存的分数。
值为 1.0 表示 GPU 上的所有可用内存都已分配。
小于 1.0 的值表示 GPU 未被超额认购
大于 1.0 的值可以解释为给定 GPU 的超额认购量。例如,具有 32 GB 内存的 GPU 的超额订阅因子值为 1.5 意味着使用统一内存分配了 48 GB 内存。
我们在微基准测试中测试了三种内存访问内核:网格步长、块边和随机每扭曲。网格跨步和块跨步是许多 CUDA 应用程序中最常见的顺序访问模式。然而,非结构化或随机访问在新兴的 CUDA 工作负载中也非常流行,如图形应用程序、哈希表和推荐系统中的嵌入。我们决定测试这三个。
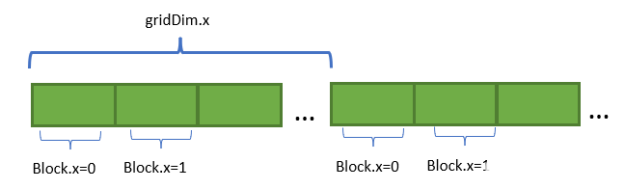
网格步长
每个线程块在循环迭代中访问相邻内存区域中的元素,然后进行网格跨步(blockDim.x * gridDim.x)。
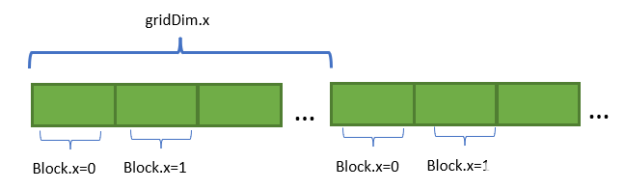
图 1 网格访问模式
template
__global__ void read_thread(data_type *ptr, const size_t size)
{
size_t n = size / sizeof(data_type);
data_type accum = 0;
for(size_t tid = threadIdx.x + blockIdx.x * blockDim.x; tid < n; tid += blockDim.x * gridDim.x)
accum += ptr[tid];
if (threadIdx.x == 0)
ptr[0] = accum;
}
挡步
每个线程块访问一大块连续内存,这是根据分配的总内存大小确定的。在任何给定的时间, SM 上的驻留块都可以访问不同的内存页,因为分配给每个块的内存域很大。
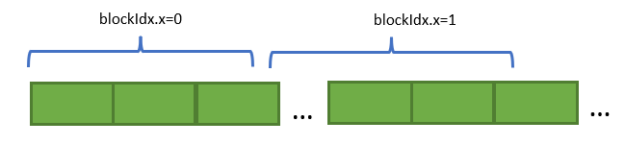
图 2 块跨步访问模式
template
__global__ void read_thread_blockCont(data_type *ptr, const size_t size)
{
size_t n = size / sizeof(data_type);
data_type accum = 0;
size_t elements_per_block = ((n + (gridDim.x - 1)) / gridDim.x) + 1;
size_t startIdx = elements_per_block * blockIdx.x;
for (size_t rid = threadIdx.x; rid < elements_per_block; rid += blockDim.x) {
if ((rid + startIdx) < n)
accum += ptr[rid + startIdx];
}
if (threadIdx.x == 0)
ptr[0] = accum;
}
随机翘曲
在此访问模式中,对于 warp 的每个循环迭代,选择一个随机页面,然后访问一个连续的 128B ( 4B 的 32 个元素)区域。这将导致线程块的每个扭曲跨所有线程块访问随机页面。扭曲的循环计数由扭曲的总数和分配的总内存决定。

图 3 随机扭曲访问模式,扭曲的每个循环迭代选择一个随机页面并访问页面中的随机 128B 区域
内核使用线程块和网格参数启动,以实现 100% 的占用率。内核的所有块始终驻留在 GPU 上。
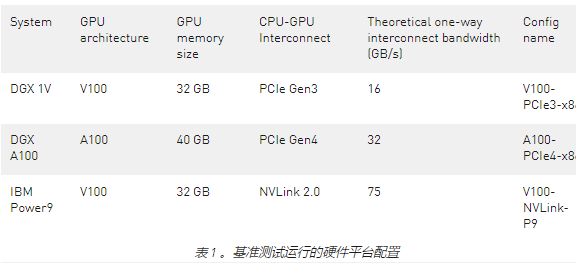
硬件设置
本文中的基准测试使用了以下三种不同硬件设置中的一种 GPU 。
我们研究了不同的内存驻留技术,以提高这些访问模式的超额订阅性能。从根本上说,我们试图消除统一内存页错误,并找到最佳的数据分区策略,以获得基准测试的最佳读取带宽。在本文中,我们将讨论以下内存模式:
按需 MIG 定额
Zero-copy
CPU 和 GPU 之间的数据分区
在下面的部分中,我们将深入到性能分析和所有优化的解释中。我们还讨论了哪些工作负载能够与统一内存一起很好地解决超额订阅问题。
基线实施:按需 MIG 定额
在此测试用例中,使用cudaMallocManaged执行内存分配,然后按照以下方式在系统( CPU )内存上填充页面:
cudaMallocManaged(&uvm_alloc_ptr, allocation_size);
// all the pages are initialized on CPU
for (int i = 0; i < num_elements; i++)
uvm_alloc_ptr[i] = 0.0f;
然后,执行 GPU 内核,并测量内核的性能:
read_thread<<<grid, block,="" 0,="" task_stream="">>>((float*)uvm_alloc_ptr, allocation_size);</grid,>
我们使用了上一节中描述的三种访问模式之一。这是使用统一内存进行超额订阅的最简单方法,因为程序员不需要提示。
在内核调用时, GPU 尝试访问驻留在主机上的虚拟内存地址。这会触发一个页面错误事件,导致通过 CPU – GPU 互连将内存页面 MIG 分配到 GPU 内存。内核性能受生成的页面错误模式和 CPU – GPU 互连速度的影响。
页面错误模式是动态的,因为它取决于流式多处理器上块和扭曲的调度。然后是 GPU 线程发出的内存加载指令。

图 4 grid stride ` read _ thread `内核执行的 NVIDIA NSight 系统时间线视图。内存行上显示的 HtoD 和 DtoH 传输是由于 MIG 定量和从 GPU 从页面错误中逐出造成的。
图 5 显示了如何在空 GPU 和超额订阅 GPU 上处理页面错误。在超额订阅时,首先将内存页从 GPU 内存移出到系统内存,然后将请求的内存从 CPU 转移到 GPU 。

图 5 页面错误服务和数据逐出机制。
图 6 显示了使用 Power9 CPU 在 V100 、 A100 和 V100 上通过不同访问模式获得的内存带宽。

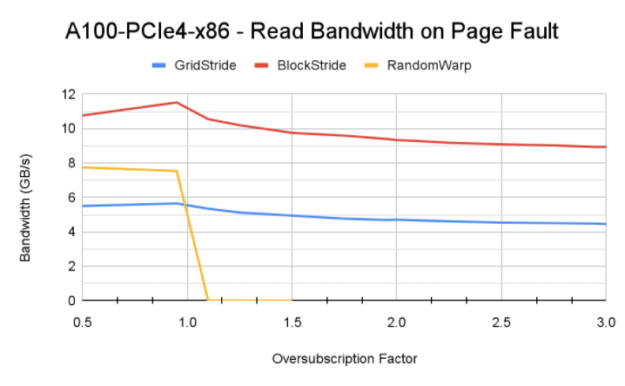
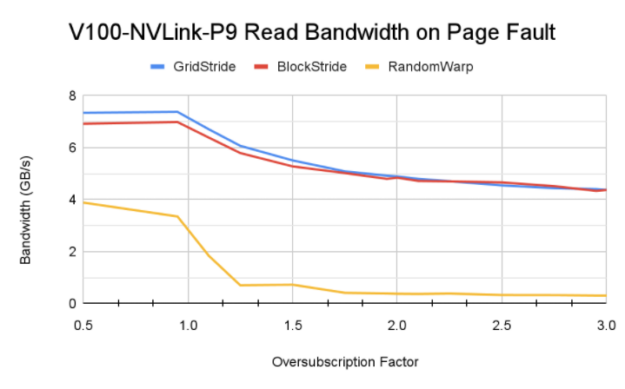
图 6 基线内存分配的读取带宽
顺序存取分析
访问模式和不同平台之间页面故障驱动的内存读取带宽的差异可以通过以下因素来解释:
访问模式的影响:传统上,已知网格跨步访问模式在访问 GPU 驻留内存时可实现最大内存带宽。这里,由于该模式生成的页面错误通信量,块跨步访问模式实现了更高的内存带宽。还值得注意的是, Power9 CPU 上的默认系统内存页大小为 64 KB ,而 x86 系统上为 4 KB 。这有助于在触发页面错误事件时,统一内存错误 MIG 将较大的内存块从 CPU 移动到 GPU 。
对 GPU 体系结构和互连的敏感性: DGX A100 在 CPU 和 GPU 之间具有更快的 PCIe Gen4 互连。这可能是 A100 实现更高带宽的原因。然而,互连带宽并不是饱和的。更高带宽的主要因素是 A100 GPU 和 108 个流式多处理器可以产生更多的页面错误,因为 GPU 上有更多的活动线程块。 P9 测试也证实了这一理解,尽管 GPU – CPU 之间的 NVLink 连接理论峰值带宽为 75 GB / s ,但读取带宽低于 A100 。
Tip:在这篇文章的实验中,我们发现流式网格和块跨步内核访问模式对线程块大小和块内同步不敏感。但是,为了使用讨论的其他优化方法获得更好的性能,我们在一个块中使用了 128 个线程,在每个循环展开时进行块内同步。这确保了块的所有扭曲有效地使用 SM 的地址转换单元。要了解块内同步的内核设计,请参阅本文发布的源代码。尝试使用不同块大小的同步和不同步变体。
随机存取分析
在 x86 平台的超额订阅域中,由于许多页面错误以及由此产生的从 GPU 到 GPU 的内存 MIG 比率,随机扭曲访问模式仅产生几百 KB / s 的读取带宽。由于访问是随机的,因此使用了 MIG 额定内存的一小部分。额定为 MIG 的内存可能最终被逐出回 CPU ,以便为其他内存片段腾出空间。
但是,在 Power9 系统上启用了访问计数器,从而从 GPU 进行 CPU 映射内存访问,并且并非所有访问的内存片段都立即被 MIG 评级为 GPU 。这导致了一致的内存读取带宽,与 x86 系统相比,内存抖动更少。
优化 1 :直接访问系统内存(零拷贝)
除了通过互连将内存页从系统内存移动到 GPU 内存之外,您还可以直接从 GPU 访问固定系统内存。这种内存分配方法也称为零拷贝内存。
可使用 CUDA API 调用cudaMallocHost或通过将虚拟地址范围的首选位置设置为 CPU ,从统一内存接口分配固定系统内存。
cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId);
cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetAccessedBy, current_gpu_device);

图 7 grid stride ` read _ thread `内核直接访问固定系统内存的 NVIDIA NSight 系统时间线视图。没有任何页面错误事件或任何方向的内存传输。
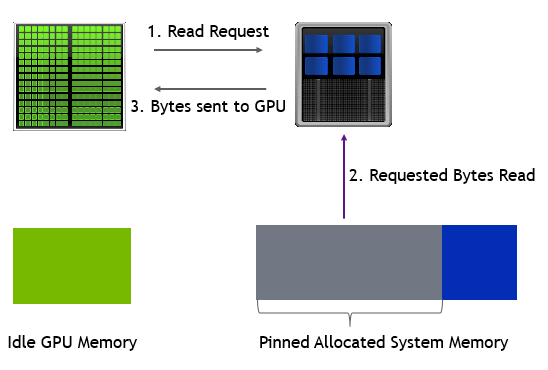
图 8 零拷贝内存的数据访问路径
图 9 显示了读内核实现的内存带宽。在 x86 平台上, A100 GPU 可以实现比 V100 更高的带宽,因为 DGX A100 上 CPU 和 GPU 之间的 PCIe Gen4 互连速度更快。类似地, Power9 系统通过网格跨步访问模式实现接近互连带宽的峰值带宽。 A100 GPU 上的网格跨步带宽模式会随着过度订阅而降低,因为 GPU MMU 地址转换未命中会增加加载指令的延迟。
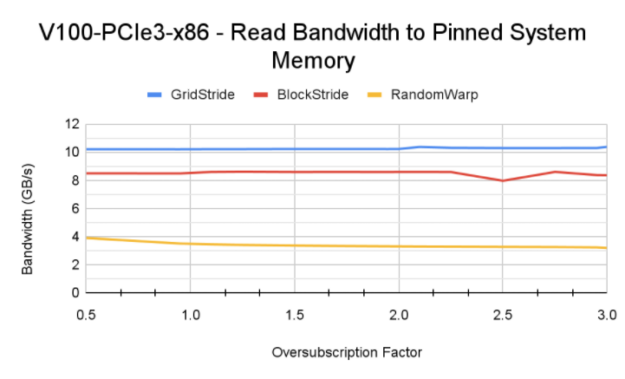
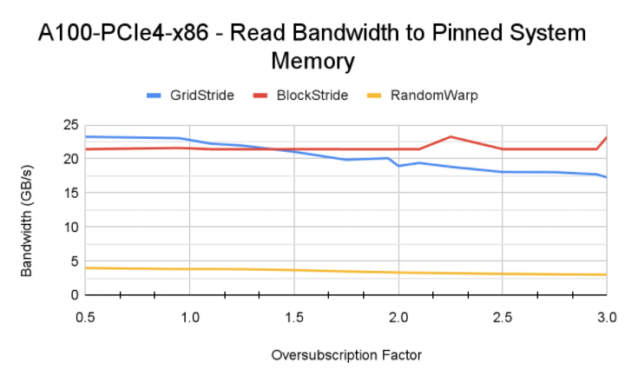
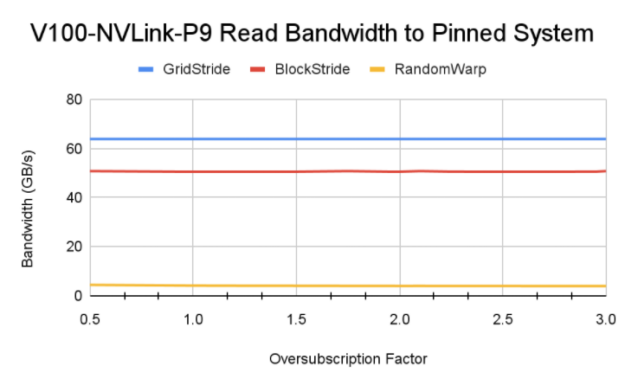
图 9 零拷贝内存的内存读取带宽
对于所有测试的系统,随机扭曲访问在超额订阅域中产生 3-4 GB / s 的恒定带宽。这比前面介绍的故障驱动场景要好得多。
收获
从数据中可以清楚地看出,零拷贝方法实现了比基线更高的带宽。当您希望避免从 CPU 和 GPU 取消映射和映射内存时,固定系统内存是有利的。如果应用程序只使用分配的数据一次,那么使用零拷贝内存直接访问更好。但是,如果应用程序中存在数据重用,则根据访问模式和重用情况,对 GPU 的错误和 MIG 评级数据可以产生更高的聚合带宽。
优化 2 :在 CPU – GPU 之间进行数据分区的直接内存访问
对于前面解释的故障驱动 MIG 比率, GPU MMU 系统在 GPU 上达到所需的内存范围之前会出现额外的暂停开销。为了克服这一开销,您可以在 CPU 和 GPU 之间分配内存,并将内存从 GPU 映射到 CPU ,以便于无故障内存访问。
在 CPU 和 GPU 之间分配内存有几种方法:
为内存分配设置了SetAccessedBy统一内存提示的cudaMemPrefetchAsync API 调用。
CPU 和 GPU 之间的手动混合内存分配,带有手动预取和使用SetPreferredLocation和SetAccessedBy提示。
我们发现,这两种方法在许多访问模式和体系结构组合中表现相似,只有少数例外。在本节中,我们主要讨论手动页面分发。您可以在unified-memory-oversubscription GitHub repo 中查找这两者的代码。
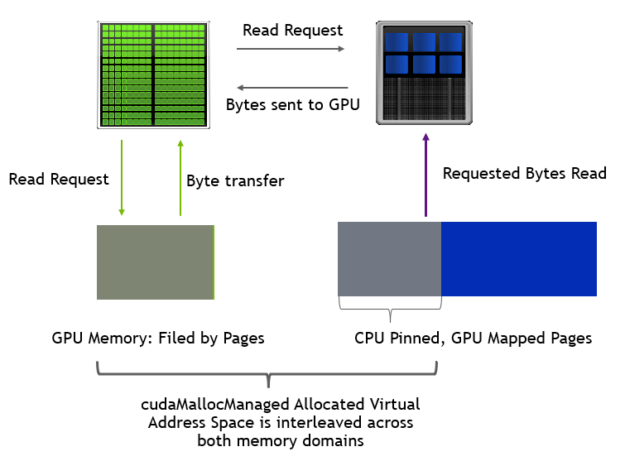
图 10 分配到 GPU 和 CPU 内存的页的内存访问路径
在混合内存分发中,很少有内存页可以固定到 CPU ,并使用cudaMemAdvise API 调用将setAccessedBy提示设置为 GPU 设备显式映射内存。在我们的测试用例中,我们以循环方式将多余的内存页映射到 CPU ,其中到 CPU 的映射取决于 GPU 的超额订阅量。例如,在超额订阅因子值为 1 。 5 时,每三个页面映射到 CPU 。超额认购系数为 2 。 0 时,每隔一页将映射到 CPU 。
在我们的实验中,内存页设置为 2MB ,这是 GPU MMU 可以操作的最大页大小。
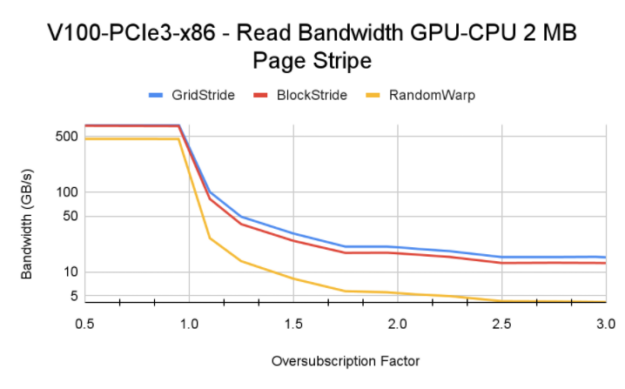
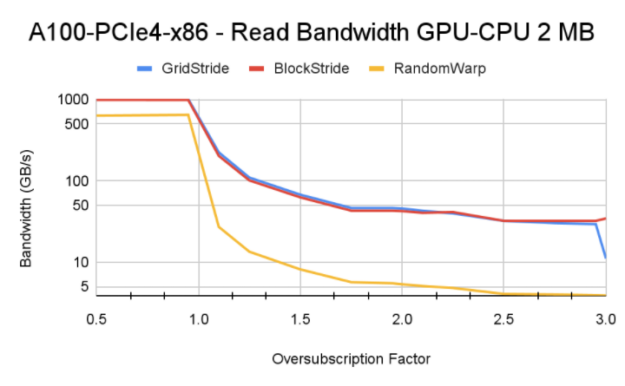
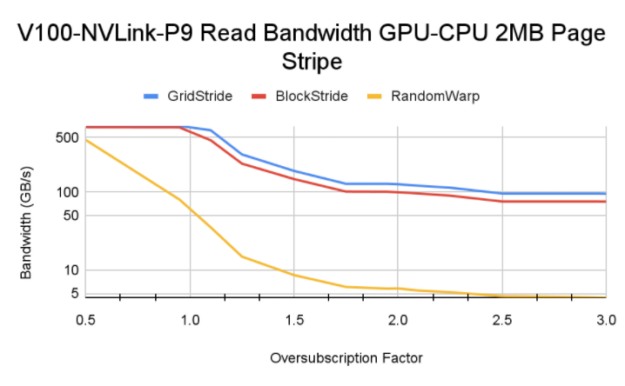
图 11 分布在 CPU 和 GPU 的 2MB 页面。 Y 轴使用对数刻度。
对于小于 1 。 0 的超额订阅值,所有内存页都驻留在 GPU 上。与超额认购率大于 1 。 0 的情况相比,您可以看到更高的带宽。对于大于 1 。 0 的超额订阅值,基本 HBM 内存带宽和 CPU – GPU 互连速度等因素控制最终内存读取带宽。
Tip:在 Power9 系统上进行测试时,我们遇到了显式大容量内存预取的有趣行为(选项 a )。因为在 P9 系统上启用了访问计数器,所以移出的内存并不总是固定在 GPU 上,统一内存驱动程序可以启动从 CPU 到 GPU 的数据 MIG 分配。这将导致从 GPU 逐出,并且该循环将在内核的整个生命周期内持续。这个过程会对流块和网格步长内核产生负面影响,并且它们比手动页面分发获得的带宽更低。
解决方案:单一 GPU 超额认购
在使用统一内存的 GPU 超额订阅的三种不同内存分配策略中,给定应用程序分配方法的最佳选择取决于内存访问模式和 GPU 内存的重用。
当您在故障和固定系统内存分配之间进行选择时,后者在所有平台和 GPU 上的性能始终更好。如果内存子区域的 GPU 驻留从总体应用程序速度中受益,那么 GPU 和 CPU 之间的内存页分配是一种更好的分配策略。
尝试统一内存优化
在这篇文章中,我们回顾了一个具有一些常见访问模式的基准测试,并分析了从 x86 到 P9 ,以及 V100 和 A100 GPU s 的各种平台上的性能。您可以使用这些数据作为参考来进行预测,并考虑在代码中使用统一内存是否有益。我们还介绍了多种数据分布模式和统一内存模式,它们有时会带来显著的性能优势。有关更多信息,请参阅 GitHub 上的unified-memory-oversubscription微基准源代码。
![]()