

是的,我说的是AI的军备竞赛:)
Google刚说要30W张H100,Meta反手就下定20W张H100……然后还有一众等更贵的H800的同学
谁也不知道未来是不是真需要这么多张卡,但谁又敢不给黄教主充值信仰呢?
run、run、run,否则你就是食物了!Repeat,请鼓掌、再不鼓掌,老黄都差点忍不住现场飙中文了。

AI大模型,嗯,你知道,1024张A100组合成炼丹炉,放把火烧一个月,就能炼出一个GPT3。按A100的8卡机10W美元一台算,不考虑基建、网络、人工等费用,128x10W/36(3年折旧)+24x30x128x10KWx0.1刀/KW = 35W + 9W = 44W美元一个GPT3,童叟无欺。
哦,你要更大的GPT4、GPT5?
简单,那就找黄教主买跟多的A100,或者买更好的H100?只要你愿意充值,就能变得更大 :)
但你内心清楚,也许你看过很多历史书,很多看上去美好的事物都会有一个收益递减曲线,所以持续规模增长,嗯,你买了10W张GPGPU啊,长期来看会不会存在一些变数让人心神不宁?当前的突破也许是值得的,但是要再提升10%,还得给黄教主多充值100%信仰,兜里钱够吗?你会想是不是三年之后的大模型会在尺度增长上碰到收益递减的瓶颈,从而演化成新的,性价比更高效东西?
我认为:是,当前大模型方向的暴力计算量占比太大了,而存储偏弱。扩展性不均衡。
就像一个人记忆力好没啥用,必须反应快才聪明,这不对。
用更大规模的算力解决更大的问题并不是新鲜事,HPC这个领域这么多年下来都是这样运作的,Top500从1993年至今已经发布了30年了,它所标识的就是地球上最强(基本上就是最大)的500个超级计算器,这些计算器代表了人类可以解决的最大尺度的自然科学问题。从1993年100GFlops到2023年的1EFlops算力规模,也算是指数增长了,但是你稍作了解就好发现解决的问题的规模并不能涌现出突破性的成果。
要是充值能持续突破问题,那个对冲基金经理兼生物医学教授David E. Shaw做的Anton,单为生(chang)命(sheng)科(bu)学(lao)求解的机器,早就被他一把火烧了(某些题目有解就得拆梯子)
1、PINN,他其实是AI协助替代原算法的部分环节,加速问题解决,例如偏微分方程的加速、或矩阵迭代求解加速等等,这两年HPC领域最高奖的Gordon Bell Prize都给了这类AI。不过,坦白来讲,这类AI并不是真正的AI,而是HPC的人看到了AI在数据拟合上的价值,利用其来做一些取巧:) 但根本上,传统HPC的同学完全没想过用AI来解决问题,他们喜欢的AI是一条乖巧的狗 :)
3、大模型,这类AI是我们当前很多人认为的AGI,知识被高度抽象后融入神经元本身,这些知识已经无法直接被符号或结构化描述因此只能通过计算得到,即只能作为Weight存放。这些知识高度抽象,具有多模态能力和推理能力。
首先,自然语言作为大模型的载体是容易理解的:)语言本身就是世间万物被人类的抽象,变成了人类对世间万物的知识,AI在人类语言基础上学习会更容易理解世间万物。
当然我们也在认识到,自然语言诞生于人体的发音和听觉器官300-3400Hz的频段约束,以及人脑接收速率。理论上AI完全不需要依赖与此。改善知识的载体有助于提升attention的效率,更高效获得输入或者建设上下文依赖,但这不是最重要的,我们可以假设最终信息被抽象之后的每个item有更高的压缩就好。而这些Item也是一种Embedding,存放在大模型的FFN内部。
我一直以来就对搜推广的Embedding table和大模型的Embedding有巨大的不协调感,为什么搜推广的Embedding可以结构化的放到存储中,而大模型的Embedding只能放在FFN网络中?
今天我的理解是:大模型对知识的Embedding抽象层次太深了,导致知识被嵌入了一个万维(12288?)的隐空间中,这些Embedding与其他Embedding或者与输入的K/V/Q之间的关系是一个超巨大的维度关系,想象一下我们身在一个简单的三维空间,很容易用坐标表达我们的位置和关系(下图你得想象一下更高维度的感觉),但大模型的维度足够大,导致了你无法用结构化的方式描述他,而只能通过Matrix去计算它。
但是,直觉上来讲,这个世界的知识并不可能真正存在万维那么大的维度。从大模型FFN到搜推广的Embedding Table之间,一定存在中间解。
为什么我会有这么奇怪的想法,主要是HPC的历史就是如此。万事万物的根本规律,如果要以第一性原理来解释,那就是求解薛定谔方程:Ĥψ=Eψ,看着简单,实际是复杂度为O(N!)的维度爆炸计算方式,在尺度较小的情况下,这个计算还可以进行,但尺度持续放大后,没人会这样算,最终,HPC人在做分子动力学模拟的时候,采用的是成键力+范德华力+电场力,差不多O(N2)的复杂度。。。。。AI大模型的FFN也终将有类似的具有近场、远场分解的范德华力出现……
所以,我认为大模型要以指数性再增长,跨越收益递减曲线,再获得新的涌现能力。FFN的计算一定会被简化成某种稀疏或者K-V的算法,以Sparse稀疏或者以存代算的方式支撑模型的指数增长。知识最终会以稀疏或者某种还未知的结构化方式存储起来,嗯,存储,DRAM(不是HBM)会重新回到AI的舞台。
从1000到20W,我赌你没钱再指数增长购买黄教主的GPGPU了,新的FFN也许不再99%都是Matrix计算了,是什么呢?嗯,谣传OpenAI都想收购Tenstorrent来的(虽然老黄一个响指,Tenstorrent就能从地球上消失)。
下午一边写,我还得一边拿着棍子陪着自家的傻儿子做作业。。。。。。。啪的一声惊堂,那是告诉他别走神。
虽然我不知道我小时候是个啥德行,但从教小孩让我理解到一个事,attention也就是注意力这个事,我感觉除了宽度,还需要关注的是深度啊。。。。。
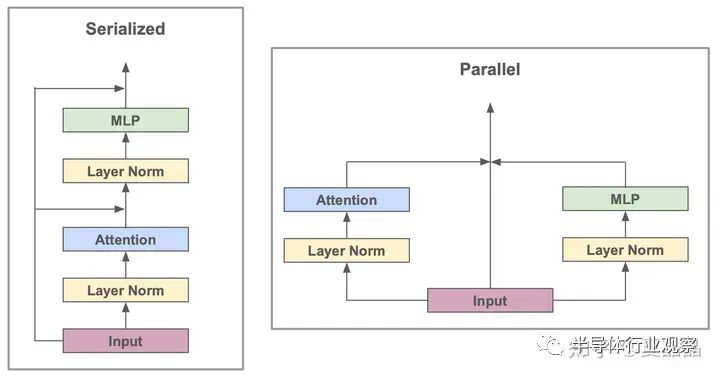
我理解:) Transformer相比传统的RNN,最大的特点就是通过self-Attenion,即多头注意力的机制,把原本基于时间维度的序列变成了一个Parallel的并发。
白话说的话,正常人看书是逐词逐句地阅读,但是《超体》的妹纸露西,就像transformer她可以一次性读入一页,在一页之内只需要寻找到96个Head重点即可。
为什么知识需要经过96 Layer的Embedding拟合,才能获得?北京是中国的首都有那么难吗?需要那么巨大的算力才能获得答案?
我家傻儿子能秒答他的iPad放在什么地方或者他喜欢的动画片里面的某些事物,但是让他做十道两位数的乘法的话,他得拼劲把眼珠子都瞪出来的注意力才能进行计算,看得出很烧脑,功耗在上升,很快就突破了散热和供电的工程约束然后就分神了。
很明显,我感觉到处理不同的知识需要的模型Layer层数是不一样的,并不是所有的知识都需要激活96 Layer那么巨大的算力。
而这我感觉并不是简单MoE的结构,而是在网络入口,或者某些的层级有一个奇怪的搜索算法,在非对称的二叉树结构上,做了一次Layer路径搜索,大幅节省了真实算力的诉求。
或者说,网络的不同层数代表了不同的行为特征,记忆、观察、推导、深思……不同的行为诉求应当激发不同的深度。
大模型的分支判定和并发结构会成为模型持续增长后的更高效的结构,即最终的大模型会变成稀疏大模型,存储占比将提升,重新作为模型不同路径的上下文回到AI大模型的大舞台,我觉得这个并发大模型不是MoE,而且结构和Nvidia的8卡GPU的互联大概率长得不一样。
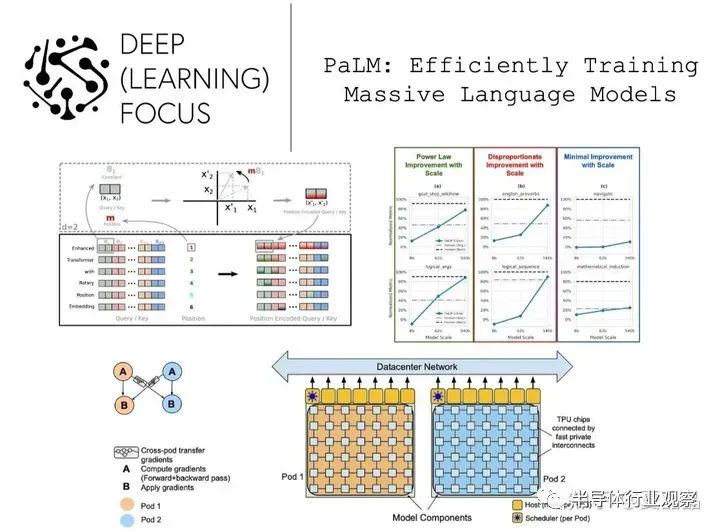
如果要在业界找个参照的话(下图左为GPT,右为palm),我感觉Google的Palm才是更像真实的完备智能体的样子,而OpenAI的GPT也许更适合做一个纯粹的YY幻想机?
如果Palm指示了正确的路径的话,他是在6144颗TPU上基于空间计算的策略训练出来的。
我曾经非常喜欢和坚定相信刘慈欣的一篇短篇《朝闻道》。
…图像定格,一声尖利的鸣叫响起,排险者告诉人们,预警系统报警了。“为什么?”总工程师不解地问。“这个原始人仰望星空的时间超过了预警阀值,已对宇宙表现出了充分的好奇,到此为止,已在不同的地点观察到了十例这样的超限事件,符合报警条件。”“如果我没记错的话,你前面说过,只有当有能力产生创世能级能量过程的文明出现时,预警系统才会报警。” “你们看到的不正是这样一个文明吗?”排险者露出那毫无特点的微笑说:“这很难理解吗?当生命意识到宇宙奥秘的存在时,距它最终解开这个奥秘只有一步之遥了。”看到人们仍不明白,他接着说:“比如地球生命,用了四十多亿年时间才第一次意识到宇宙奥秘的存在,但那一时刻距你们建成爱因斯坦赤道只有不到四十万年时间,而这一进程最关键的加速期只有不到五百年时间。如果说那个原始人对宇宙的几分钟凝视是看到了一颗宝石,其后你们所谓的整个人类文明,不过是弯腰去拾它罢了。”

如果静下心来认真思索一下,我们会发现,碳基的肉体(文明的容器)所具有的局限性最终会阻碍我们。
智慧,或者文明的演进是基于能效提升而逐步进化的。
吃肉的肉食动物就往往比草食动物厉害,而猴子之所以能够变成智人,也都是伴随着食物烹饪、咀嚼带来的对能量的更高效的利用,使得大脑有更多的能量而增大直至涌现智能。
而今天,碳基生物的人类吃得再多,只会长肉或者让一部分人吃饱了撑的慌,并不能变得更聪明了。而硅基吃电……
文明的本质,就是持续把能量转换为负熵。只要宇宙没有尽头,那么这个转换过程就应当是无止境的。具有越高级别转换效率及越强烈转换欲望的文明,才是最终的那个文明。
所以,并不是因为碳基肉体的脆弱(硅基也脆弱),而是因为碳基生物的生物欲望度太低级了。吃喝嫖赌就能让碳基生物获得无以伦比的满足,当科技发展到今天,满足70%碳基生物最原始的DNA需求实在是太容易了,也许是有musk这类人具有更高欲望,但数量已经稀少。什么财富自由?什么躺平?不就是碳基欲望基本满足,熵减程度达到了其容器的上限,剩下的只余下耗散了呗。

杭州灵隐寺不是有一付著名的对联么?
“人生哪能多如意,万事只求半称心”。
写得挺好吧,正如上周日的节气,小满。
不妨把这对联当做硅基生物写给碳基生物的挽联,再把这节气当做碳基生物的祭日吧
![]()