
近年来,随着新技术以前所未有的速度出现,人工智能取得了重大飞跃。毫无疑问,ChatGPT、Bard 和 Einstein 等工具将影响各个行业——从媒体和内容创建到研究、金融等。
这些工具现在可以密切模拟人类对话,能够理解上下文信息、实时对话,并以极高的精度执行从翻译到总结的任务。
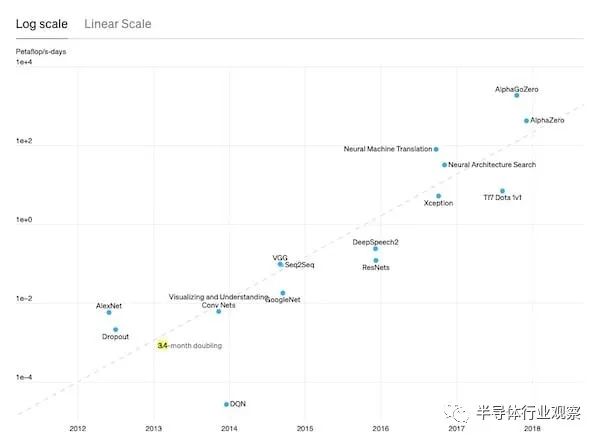
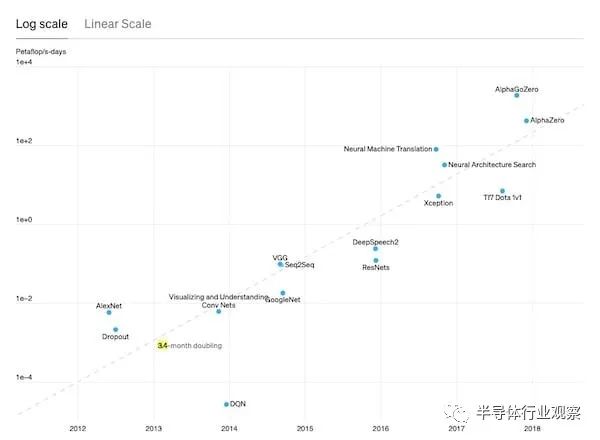
OpenAI 表示,为了了解这些 AI 技术的进步速度,“最大规模的 AI 训练运行所使用的计算量呈指数级增长,是 3.4 个月的两倍” 。回顾 80 年代和 90 年代,神经网络研究活动非常活跃,训练引擎的计算和内存与今天的能力相比非常弱。
时间快进到 2012 年,摩尔定律的不断发展使人工智能能够有效地执行分类——识别图片和视频中的对象。与此同时,自然语言处理(NLP)的发展也至关重要。
随着 Siri 等工具开始兴起,并随着这些应用程序慢慢发展和演变,显然下一步就是让它们生成。一旦这些训练算法能够快速分类信息、在数据之间建立关联并理解所提出的请求,问题就变成了它们是否可以利用这些学习成果以可识别的方式有效地组装新内容。
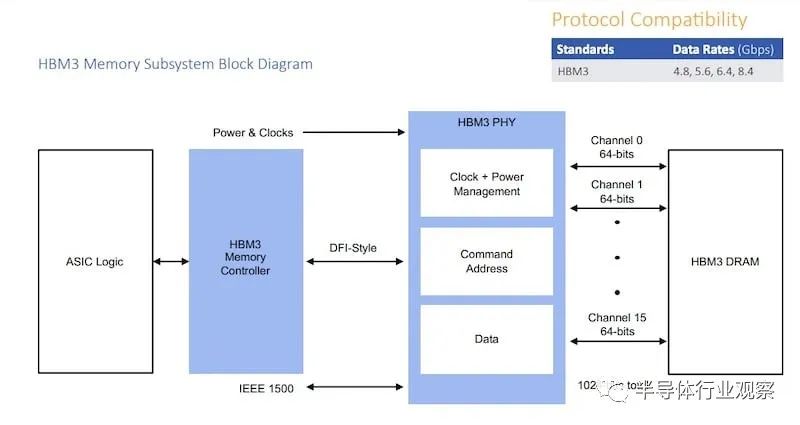
得益于半导体行业在 HBM(高带宽内存)、DDR、异构计算等方面的进步,随着我们进入生成式 AI 新时代的开始,这已成为现实。
尤其是过去十年,由于 DDR DIMM 芯片组和 HBM 接口以及特定领域计算架构的代际升级,人工智能训练和推理能力取得了巨大进步。这些都在生成式人工智能开发中发挥了关键作用,有助于提高速度、容量和连接性,以满足日益苛刻的工作负载。
用于通过生成式人工智能创建新图像、音频和文本的机器学习算法需要大量数据和快速内存才能有效运行。DDR5是 DDR 内存的最新标准,可提供更高的数据传输速率和更低的功耗,与前几代产品相比,可以在低延迟的情况下实现更高效的数据处理。
服务器本身也开始转向异构计算架构,因为越来越多地使用专用加速器来卸载 CPU 上的专用工作负载。一个示例异构计算系统由 CPU、AI 加速器和网络处理器组成。
它们各自可以执行不同类型的计算,以实现生成式人工智能,因为复杂的计算可以在专用处理单元上更快地执行。例如,CPU 将用于通用处理任务,并且可以将某些任务卸载到人工智能加速器等专用处理器。
AI加速器可以加速张量运算,提高神经网络训练和推理的速度。网络处理器可以提高数据通过网络移动到服务器中的CPU和AI加速器的速度。
通过利用每个处理单元的优势,生成式人工智能可以以更高的效率提供高质量的数据。处理器和 CXL 等新标准促进的内存缓存一致性在这方面也发挥着关键作用,因为它支持 CPU 和加速器之间的内存资源共享。
就在过去的几个月里,我们看到 ChatGPT 取得了突飞猛进的进步。根据ABA Journal 的一篇文章,这项曾经在 2022 年 11 月进行试验的新技术现在已经足以在几个月后通过律师考试,排名前 10% 。
虽然当前的能力展示了人工智能令人印象深刻的潜力,但它们仅仅触及了未来可以实现的目标的表面。当我们开始考虑这些技术如何彻底改变我们的沟通和开展业务的方式时,一个新的问题出现了:生成人工智能的下一个可能阶段是什么?
硬件的快速发展表明,行业很快就达到了现有硬件的极限。为了继续推动人工智能向前发展,为生成式人工智能提供动力的硬件必须具有更先进的计算能力以及更高带宽的内存互连和存储。这将需要半导体行业的快节奏创新,以及解决内存和处理之间瓶颈的承诺和协调努力。
如果没有半导体行业生产更快的芯片和互连的能力,在过去 11 年里,最大规模的 AI 训练运行所使用的计算量不会增长 300,000 倍。
即将出现的新技术展示了业界在推进内存技术和探索新架构以继续改进人工智能方面的投资。
![]()