
2023年3月29日,IC和系统设计盛会“国际集成电路展览会暨研讨会(IIC Shanghai)”在上海国际会议中心拉开帷幕。奇异摩尔受邀参加首日举办的EDA/IP与IC设计论坛,发表主题为《基于Chiplet的超大规模异构计算平台,助力AIGC逐浪狂飙》的演讲,与现场嘉宾、观众们深度探讨了Chiplet与AIGC两大热点的技术趋势。
最近AIGC成为了行业中的热点话题,它在不同领域的应用层出不穷,如微软的Copilot和Midjourney等。随着AIGC的飞速发展,对算力也提出了更高的要求。
AIGC的发展对算力的需求变化
回顾AI的发展史,十几年间,AI从决策式和小模型计算发展到大模型,AI对我们的生产方式以及使用方式的影响日渐显性化,对企业的商业模式也有着巨大的影响。
生成式AI的模型类型和应用方式不断增加,市场上出现了很多出色的应用,产业迭代的速度肉眼可见的超过了市场接受的反应。但是,AI快速迭代背后的因素是大模型所带来的能力突变。AI的能力准确率已经达到了人类基准线以上,这种准确率的提高需要更大规模的模型和算力,与此同时,AI对算力的依赖会变得越来越强。
所谓“算力依赖”主要体现在四个层面,算法、数据、工程以及算力。算法是相对成熟的,但数据层面随着算法的推进,在以指数级的速度在上升。工程和算力则会面临更大的挑战:如何用更少的人工干预、更少的算力产生更高的效能?
AI的迭代速度非常快,每一代所需要的模型数量、算力规模比上一代都有数倍甚至一倍的速度增加,远远超过了我们能够提供的增长曲线,从而为行业提出了新的命题和挑战。这样的挑战会给高性能计算带来怎样的变化?
大模型对高性能计算架构有哪些影响
在高性能计算领域,除了算力挑战以外,挑战主要来自于三个方面:如何提高算力功耗比,如何提高存储访问的功耗比,以及如何提高互联效率。
过去以同构和板卡级互联为特点的数据中心架构,很难支撑未来超大规模计算的需求,数据中心架构需要从顶层开始重新设计以满足超大规模计算的需求。
国际巨头们正在采取不同的方式应对这些挑战:NVIDIA使用NVLINK3.0和InfiniBand来形成超大规模集群,并将CPU和GPU组合在一起处理数据集,以应对未来数据中心的算力需求;Intel去年年底发布了第一款3D GPGPU,未来还计划发布3D APU,致力于提供更好的集联和互联性能,在不同的领域可以用最合适的芯片去解决相关的问题;而AMD则发布了自己的3D APU产品 MI300。
超大规模集群已经成为未来的发展方向,其中异构也是非常重要的趋势。在这个趋势里,Chiplet 预期将成为超大规模集群未来的核心。
超大规模计算集群核心技术
超大规模计算集群技术需要一个有效的架构来调度更大规模的算力算子进行集联。此前的计算架构都局限于64核或148核,但特斯拉通过25颗die组成了上千个CPU的超大集群,这对软件和硬件架构都提出了挑战。
同时,统一的编程框架和库模型也很关键,国内也有很多在这方面的合作伙伴,未来同样会成为一个非常重要的发展方向。
第三,未来,各种芯粒都有可能成为单元,包括CPU、GPU、NPU等等。这样做的好处是避免了重复设计,可以单独迭代,同时可以组成不同的产品系列。然而,如何将这些芯粒连接在一起,降低传输损耗,提高效率,仍然是非常大的挑战。
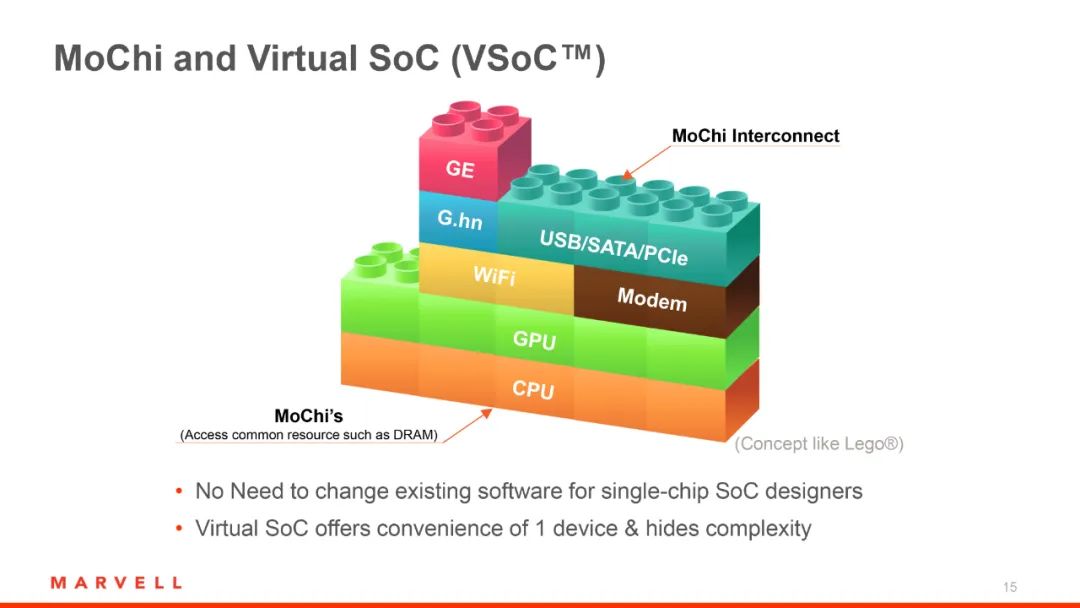
什么是Chiplet?
Chiplet是一种新的芯片设计方法,它基于 SoC 架构进行拆分重组,将主要功能单元 (IP) 转变成独立芯粒 (Dielet),并通过先进封装和 Die-to-Die接口,将芯粒连接到 Chiplet 互联网络 (OCI) 中,组成系统级宏芯片 (MSoC)。
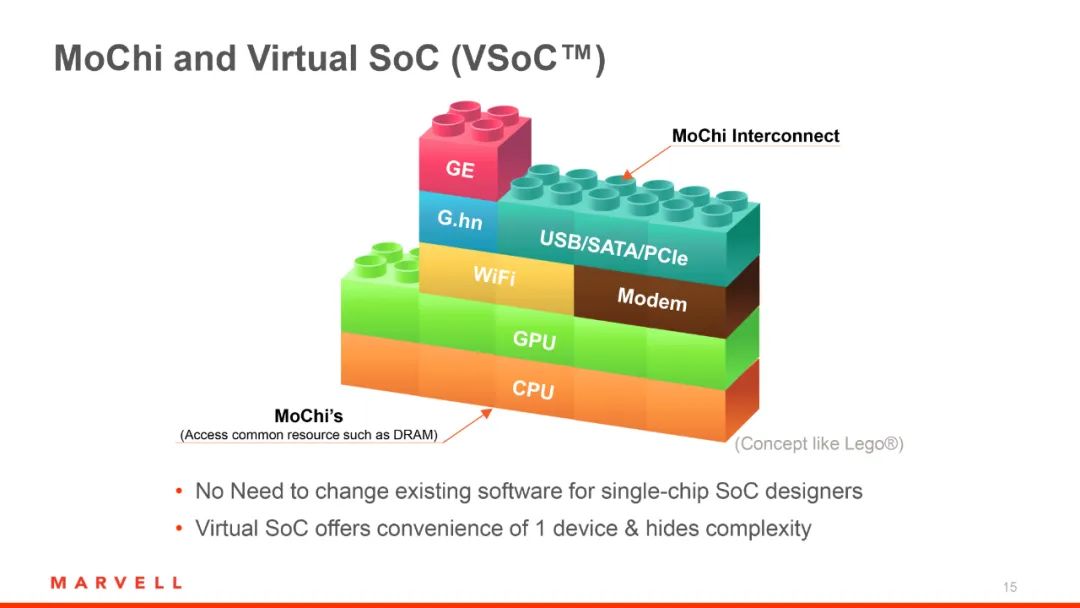
通过Chiplet设计,可以持续扩大芯片面积,提升性能,并且减少研发成本和芯片面积,同时增加芯片良率,保持经济和成本的可行性。AMD已经成功地应用了这种设计方法,我们也可以通过这种方式来打造更好的产品组合。
(文章来源:奇异摩尔)
![]()