在全球范围内,如果智能手机和移动设备市场有一个普遍不变的常数,那就是 Arm。无论是移动芯片制造商将他们的 SoC 基于 Arm 的完全合成 CPU 内核,还是仅仅依靠 Arm ISA 并设计他们自己的芯片,归根结底,Arm 几乎是所有这一切的基础。这种市场饱和度和相关性证明了 Arm 在过去几十年中为达到这一点所做的所有艰苦工作,但这也是一项重大责任——对于大多数移动 SoC 而言,它们的性能只会以最快的速度向前发展Arm 自己的 CPU 内核设计和相关 IP 可以。
因此,我们已经看到 Arm 为他们的客户 IP 设定了年度节奏,今年也不例外。为了配合今年在台湾举行的 Computex 贸易展,Arm 展示了一套新的 Cortex-A 和 Cortex-X 系列 CPU 内核——以及新一代 GPU 设计——我们将看到它们为Arm 从今年晚些时候开始,一直持续到 2024 年。其中包括旗舰 Cortex-X4 内核,以及 Arm 的中核 Cortex-A720。以及新的小核 Cortex-A520。
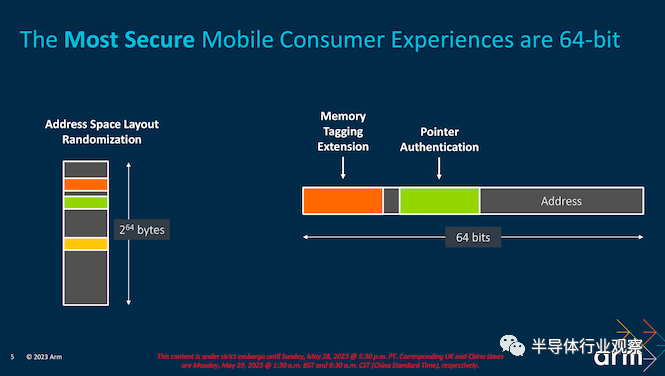
Arm 的最新 CPU 内核建立在 Armv9 及其整体计算解决方案 (TSC21/22) 生态系统的基础上。对于他们的 2023 IP,Arm 正在通过其 Cortex 内核系列推出一波次要的微架构改进,这些细微的变化旨在提高效率和性能,同时完全转向 AArch64 64 位指令集。Arm 的最新 CPU 设计也旨在与全行业不断提高安全性的努力保持一致,虽然这些功能并非严格面向最终用户,但它确实强调了 Arm 的世代改进不仅仅是性能和功率效率。
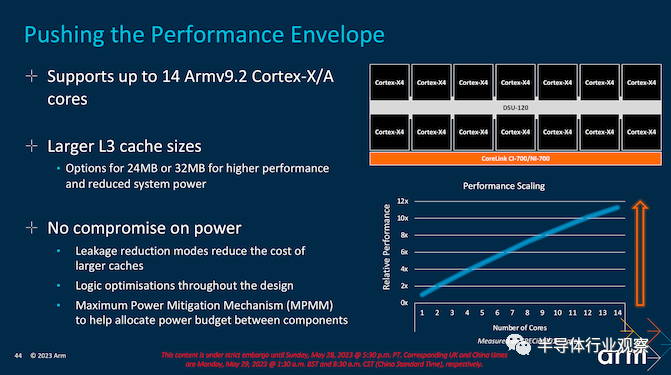
除了改进其 CPU 内核外,Arm 还使用 DSU-120 对其 DynamIQ Shared Unit 内核复合块进行了全面升级。尽管引入的修改很细微,但它们在提高将 Arm CPU 内核保持在一起的结构效率方面具有重要意义,同时在性能可扩展性方面进一步扩展 Arm 的范围,支持单个块中多达 14 个 CPU 内核– 此举旨在使 Cortex-A/X 更适合笔记本电脑。
有了三个新的 CPU 核心和一个新的核心复合体,有很多东西可以涵盖。所以让我们开始吧。
高水平的 Arm TCS23:提高效率并走向纯 64 位扩展去年在 Armv9.1 架构中引入的增强功能,Arm 正在使用最新的 Armv9.2 架构完成其预定的开发周期。此周期的主要目标是消除对 32 位应用程序的支持并过渡到全面的 64 位平台。支持这一转变的是 Arm 的战略框架“整体计算解决方案”(TCS),它围绕三个核心原则:计算性能、安全性和开发人员访问。这种方法构成了 Arm 方法论的基础,并指导其努力提供最佳性能、强大的安全措施和简化的开发人员能力。
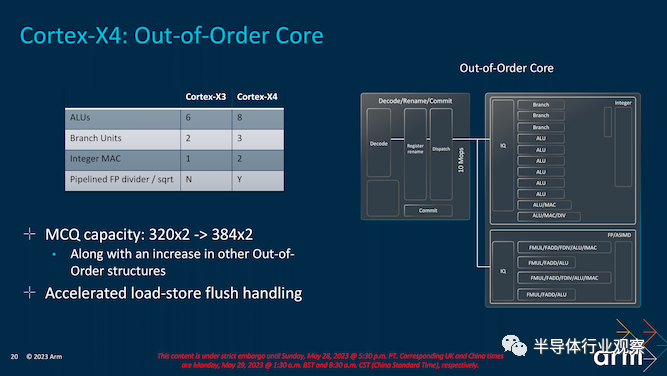
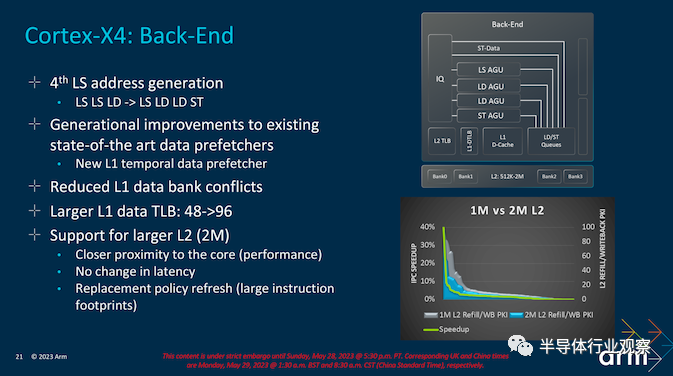
增加多通道队列 (MCQ) 容量——从而增加指令重新排序窗口的大小——是 Arm 的 Cortex-X4 工具箱的另一项改进。与之前 Arm 的重新排序缓冲区的增加一样,更大的队列提供了更多机会来寻找指令重新排序、隐藏内存停顿以及以其他方式为其余 CPU 后端提取更多机会来完成一些工作。随着 CPU 性能继续超过内存带宽,对更大缓冲区的需求只会随着每一代的增长而增长。
最后,在 X4 CPU 核心的后端,Arm 添加了第四个地址生成单元。有趣的是,这个只适用于存储;Arm 已有一个仅加载单元,但选择了一个仅存储单元,而不是将其转换为完全混合的 LS 单元。
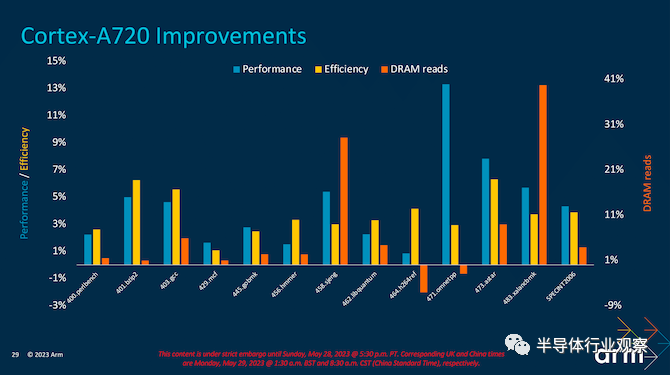
提供的其他性能指标包括 DRAM 读取,Arm 将大量注意力集中在提高效率上,总体上显示出较小的收益;SPEC2007int_483.xalacbmk 显示 DRAM 读取性能大幅提升高达 41%。虽然一切都与任务的工作负载相关且主观,但 Arm 凭借其最新的 Cortex-A720 CPU 核心微架构取得了一些明显的进步。
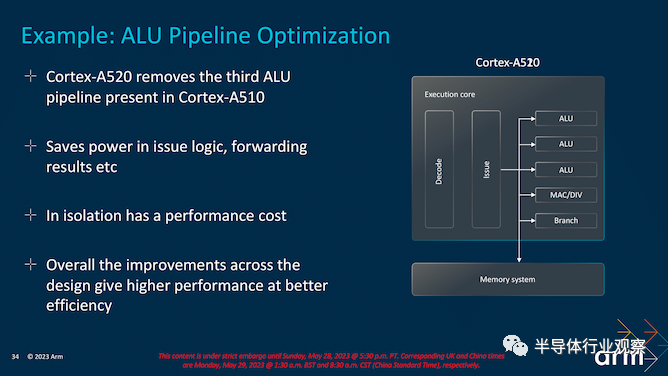
Cortex-A520:大改进的小内核Armv9.2 内核中的第三个是 Cortex-A520,它的设计很少,但 Arm 承诺比前几代有很大改进,尤其是在能效方面。
立即解决最大的问题:不,Cortex-A520 不是乱序内核设计。忠于 Arm 的小核心设计理念,它仍然是有序核心——事实上,Arm 甚至在此过程中移除了 ALU。
Arm 的 Armv9.2 公告的关键要点是他们的 IP 将完全绑定到一个完整且完整的 64 位生态系统,并且他们希望利用更统一的市场带来的所有好处。
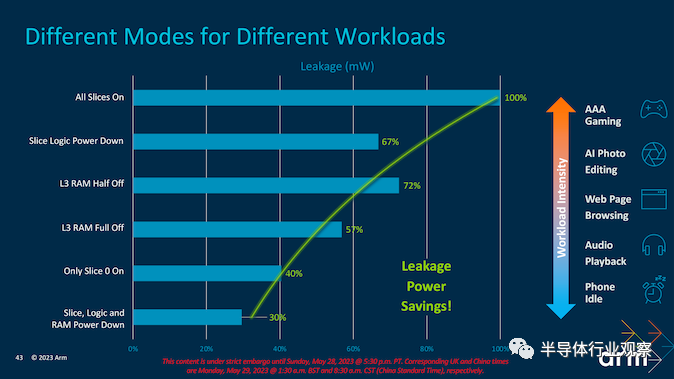
即使从技术的角度来看,为了提高效率而改进现有的 TCS22 IP 也不是前卫的。它更多地是关于改进当前的 IP 以适应更广泛的市场对效率的关注。从我们所看到的情况来看,大部分收益都来自于通过诸如 RAM 断电和 Slice 断电等实施来减少特定的电源结构,以尽可能节省能源,并允许将节省的电力用于其他领域;或者根本不节省设备电池寿命。
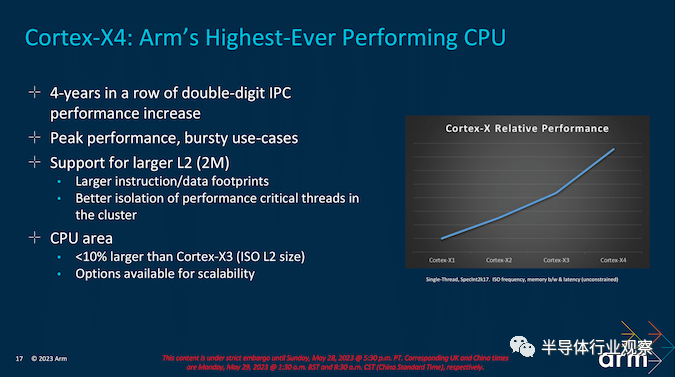
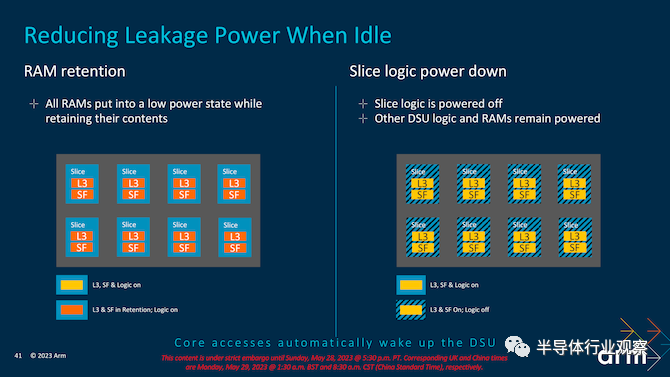
Arm 进一步提高了其所有三个新内核的能效,Cortex-X4 是 Arm 创造的最快的内核,一直到中间的 Cortex-A720 和小的 Cortex-A520 内核。在每个内核中找到功率和性能提升,可以对整体效率产生更显着的影响,这正是 Arm 多年来一直在做的事情。即使是最新的 DynamIQ Shared Unit (DSU-120) 也通过使用动态功耗和各种空闲电源模式来实现活动,从性能的角度来看,这使得事情变得更加高效,尤其是在工作负载不密集并且可以分配给正确的内核,特定的逻辑片可以断电以最大限度地提高效率。
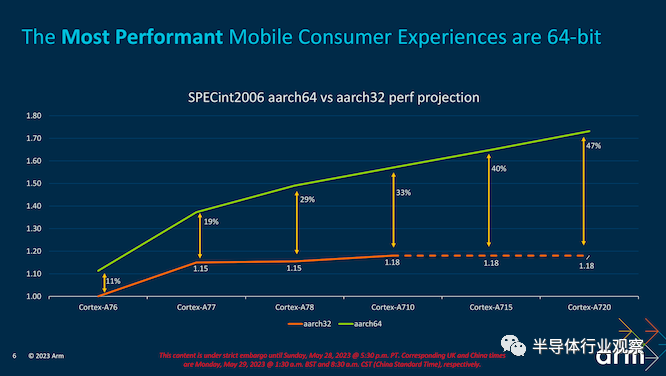
同时,向纯粹的、仅 64 位的 AArch64 ISA 的转变在不同领域产生了许多改进。对于 Arm 的 IP 团队,它允许 Arm 在我们推进时将其工作直接集中在一个特定的 ISA 上。尽管如此,它还在其软件中实现了对等,其中 Arm 的软件工程人员占其整个工程团队的 45%。这是一大笔人力致力于在软件、硬件和 IP 之间的差距中进行改进,并推动 64 位 ISA 生态系统进一步走向完全统一的市场空间。性能优势和基于安全的优势在 32 位和 64 位之间的转换中普遍存在,它只是采用统一的系统,而 Arm 无疑正在鼓励市场从以前的产品转向,包括新发布的 Armv9.2 架构。
虽然 OPPO 等中国公司在向 64 位迁移方面进展缓慢是出了名的,但中国市场 64 位应用程序的增长在去年呈指数级增长。64 位和 32 位之间的应用程序周期主要由谷歌及其 Play Store 驱动,其开发人员多年来需要编译 64 位版本。这一要求确保软件开发商,尤其是那些与 Arm 合作为最新的 Arm IP 优化其软件的开发商,对较慢的采用者和市场产生积极影响,促使他们最终转向 64 位。
64 位的下一步是挤出比 32 位更多的优势;一方面,安全在推动事情向前发展方面发挥着更重要的作用。AArch64 不仅性能优于 AArch32,而且 64 位 ISA 提供了更多安全选项。在简化从 IP 到硬件、到软件、到设备、再到市场的整个过程中找到效率,应该有望通过从公司计划中完全放弃 32 位来降低成本。即使对于像下一波数字电视 (DTV) 这样不断增长的市场的设备,这些供应商无疑也可以将提高的性能和安全完整性的优势应用到他们的产品中。
所有这些都与事物的制造方面密切相关。尽管 Arm 在 IP 级别改进了其设计,并在 iso-process 的基础上提供了收益,但节点缩小仍然是提高芯片性能的最有效方法,尤其是在能效方面。Arm 的 TSC23 IP 是第一个在台积电 N3E 工艺上流片的 IP 绝非侥幸,它标志着 Arm PPA 设计理念的最终组成部分。
总的来说,虽然 Arm 的 2023 CPU 和系统 IP 没有在任何层面带来任何根本的微架构变化,但总的来说它是一系列新的 IP 产品。在去年将球转向带有 Cortex-A715 的纯 64 位 CPU 内核之后,今年的最终全面转变仍需要一些时间来适应,但总体而言应该是一个相当平稳的过渡。通过这样做的同时关注他们的 SoC 客户真正关心的 PPA 的那些方面——小的裸片尺寸可以降低能耗——Arm 为他们的合作伙伴提供了两个很好的理由来继续推进其他方面公司。Arm 的合作伙伴最终制造出什么样的芯片还有待观察,但我们期待在今年晚些时候看到事情的进展。