跳至内容
 想想在不远的过去,计算机被应用到的许多任务需要人类的直觉。而现在计算机通常会识别图像中的物体、转录语音、在语言之间进行翻译、诊断医疗状况、玩复杂的游戏和驾驶汽车。
促成这些惊人发展的技术称为深度学习,这个术语指的是被称为人工神经网络的数学模型。深度学习是机器学习的一个子领域,是基于将复杂模型与数据拟合的计算机科学的一个分支。
虽然机器学习已经存在了很长时间,但深度学习最近开始了自己的新生命。其原因主要是因为越来越多的计算能力已经变得广泛可用——以及可以轻松收集并用于训练神经网络的大量数据。
在千禧年之际,人们触手可及的计算能力开始突飞猛进,当时图形处理单元 (GPU) 开始被用于非图形计算,这一趋势在过去十年中变得越来越普遍。但深度学习的计算需求增长得更快。这种动态促使工程师开发专门针对深度学习的电子硬件加速器,入谷歌的张量处理单元 (TPU)就是一个很好的例子。
在这里,我将描述解决这个问题的一种非常不同的方法——使用光学处理器,用光子而不是电子来执行神经网络计算。要了解光学如何在这里发挥作用,您需要对计算机目前如何进行神经网络计算有所了解。因此,当我概述引擎盖下发生的事情时,请耐心等待。
几乎无一例外,人工神经元是使用在某种数字电子计算机上运行的特殊软件构建的。该软件为给定的神经元提供多个输入和一个输出。每个神经元的状态取决于其输入的加权和(weighted sum),非线性函数(称为激活函数:activation function)应用于该输入。结果,这个神经元的输出,然后成为各种其他神经元的输入。
为了计算效率,这些神经元被分组到层中,神经元只连接到相邻层的神经元。与允许任何两个神经元之间的连接相反,以这种方式安排事物的好处在于它允许使用线性代数的某些数学技巧来加速计算。
虽然它们不是全部,但这些线性代数计算是深度学习中计算要求最高的部分,尤其是随着网络规模的增长。对于训练(确定将什么权重应用于每个神经元的输入的过程)和推理(当神经网络提供所需结果时)都是如此。
这些神秘的线性代数计算是什么?它们真的没有那么复杂。它们涉及对矩阵的操作,矩阵只是数字的矩形数组——电子表格,如果你愿意的话,减去你可能会在典型的 Excel 文件中找到的描述性列标题。
这是个好消息,因为现代计算机硬件已经针对矩阵运算进行了很好的优化,矩阵运算在深度学习流行之前很久就已经是高性能计算的基础。深度学习的相关矩阵计算归结为大量的乘法和累加运算,其中将成对的数字相乘并将它们的乘积相加。
多年来,深度学习需要越来越多的乘法累加运算。以LeNet 为例,这是一种开创性的深度神经网络,旨在进行图像分类。1998 年,它被证明在识别手写字母和数字方面优于其他机器技术。但到 2012 年推出的AlexNet,又是另一个神经网络,它的乘法累加运算次数是 LeNet 的 1600 倍,能够识别图像中数千种不同类型的对象。
从 LeNet 最初的成功发展到 AlexNet,需要将计算性能提高近 11 倍。在这 14 年的时间里,摩尔定律提供了大部分增长。现在的挑战是保持这种趋势,因为摩尔定律已经失去动力。通常的解决方案是在问题上投入更多的计算资源以及时间、金钱和精力。
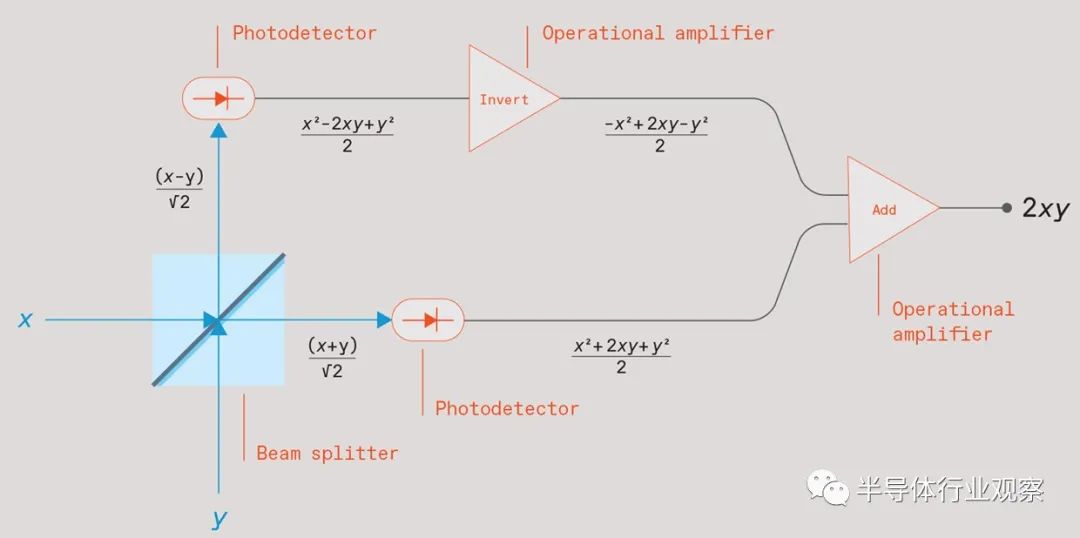
强度与要相乘的数字 x 和 y 成正比的两束光束撞击分束器 [蓝色方块]。离开分束器的光束照射在光电探测器 [椭圆形] 上,提供与光强度平方成正比的电信号. 将一个光电探测器信号反相并将其与另一个相加,就会产生一个与两个输入的乘积成正比的信号。
因此,训练当今的大型神经网络通常会产生显著的环境足迹。一个2019研究发现,例如,训练自然语言处理某深神经网络会产生一辆汽车终生驾驶所排放二氧化碳的五倍。
可以肯定的是,数字电子计算机的改进使深度学习得以蓬勃发展。但这并不意味着进行神经网络计算的唯一方法就是使用此类机器。几十年前,当数字计算机还相对原始时,一些工程师使用模拟计算机来解决困难的计算。随着数字电子技术的改进,那些模拟计算机被淘汰了。但现在可能是再次采用该策略的时候了,特别是当模拟计算可以通过光学方式完成时。
众所周知,光纤可以支持比电线高得多的数据速率。这就是为什么从 1970 年代后期开始,所有长途通信线路都采用光纤的原因。从那时起,光数据链路取代了铜线,跨度越来越短,一直到数据中心的机架到机架通信。光数据通信速度更快,功耗更低。光学计算承诺同样的优势。
但是通信数据和用它计算之间有很大的区别。这就是模拟光学方法遇到障碍的地方。传统计算机基于晶体管,晶体管是高度非线性的电路元件——这意味着它们的输出不仅与输入成正比,至少在用于计算时是这样。非线性是什么让晶体管打开和关闭,允许它们被塑造成逻辑门。这种切换很容易用电子设备来完成,因为电子设备的非线性非常重要。但是光子遵循麦克斯韦方程,这是令人讨厌的线性,这意味着光学设备的输出通常与其输入成正比。
解决问题的窍门是利用光学设备的线性来做深度学习最依赖的一件事:线性代数。
为了说明如何做到这一点,我将在这里描述一个光子设备,当它与一些简单的模拟电子设备耦合时,可以将两个矩阵相乘。这种乘法将一个矩阵的行与另一个矩阵的列组合在一起。更准确地说,它将这些行和列中的数对相乘,并将它们的乘积加在一起——我之前描述的乘法和累加运算。我和我的麻省理工学院同事发表了一篇关于如何在 2019 年做到这一点的论文。我们现在正在努力构建这样一个光学矩阵乘法器。
该设备中的基本计算单元是一个称为分束器(beam splitter)的光学元件。虽然它实际上可能更复杂,但你可以把它想象成一个 45 度角的半镀银镜子。如果你从侧面发射一束光,分束器会让一半的光直接穿过它,而另一半会从有角度的镜子反射,使它从入射光束以 90 度的角度反弹.
现在将第二束光垂直于第一束光照射到该分束器中,使其照射到成角度的镜子的另一侧。该第二光束的一半将类似地以 90 度角透射和反射。两个输出光束将与第一个光束的两个输出组合。所以这个分束器有两个输入和两个输出。
要使用此设备进行矩阵乘法,您需要生成两个光束,其电场强度与要相乘的两个数字成正比。我们称这些场强为x和y。将这两束光照射到分束器中,分束器将合并这两束光。这种特殊的分束器会产生两个输出,其电场值为 (x+y)/√2 和 (x−y)/√2。
除了分束器之外,这种模拟倍增器还需要两个简单的电子元件——光电探测器——来测量两个输出光束。不过,他们不测量这些光束的电场强度。他们测量光束的功率,该功率与其电场强度的平方成正比。
为什么这种关系很重要?要理解这一点,需要一些代数——但除了你在高中学到的知识之外,别无他物。回想一下,当你平方 (x+y)/√2 时,你会得到 (x²+2xy+y²)/2。当你平方 (x−y)/√2 时,你会得到 (x²−2xy+y²)/2。从前者中减去后者得到2xy。
现在停下来思考这个简单数学的重要性。这意味着如果你将一个数字编码为具有一定强度的光束,将另一个数字编码为另一种强度的光束,将它们发送通过这样的分束器,用光电探测器测量两个输出,并抵消产生的电信号之一在将它们相加之前,您将得到一个与两个数字的乘积成正比的信号。
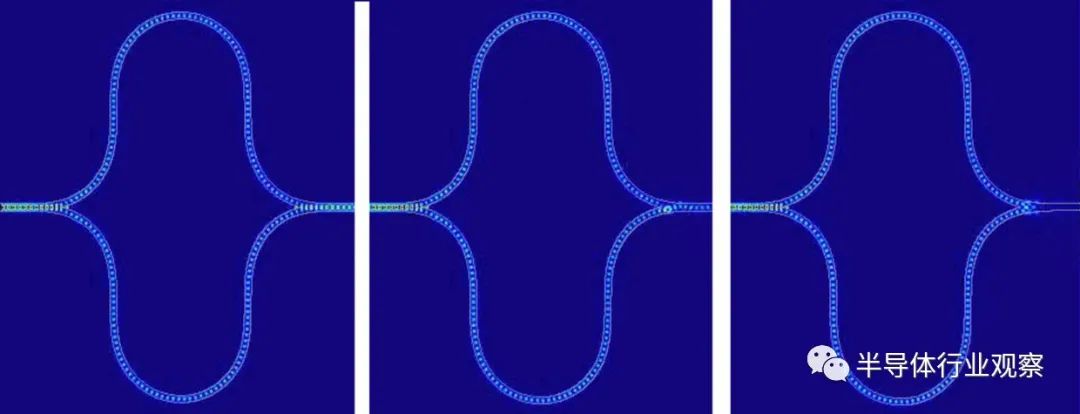
Lightmatter 神经网络加速器中集成的 Mach-Zehnder 干涉仪的模拟显示了三种不同的条件,即在干涉仪的两个分支中传播的光经历不同的相对相移。
我的描述听起来好像这些光束中的每一个都必须保持稳定。事实上,您可以在两个输入光束中短暂地脉冲光并测量输出脉冲。更好的是,您可以将输出信号馈送到电容器中,然后只要脉冲持续,它就会积累电荷。然后您可以在相同的持续时间内再次脉冲输入,这次编码两个要相乘的新数字。他们的产品为电容器增加了一些电荷。您可以根据需要多次重复此过程,每次执行另一个乘法累加运算。
以这种方式使用脉冲光可以让您以快速的顺序执行许多此类操作。其中最耗能的部分是读取该电容器上的电压,这需要一个模数转换器。但是你不必在每个脉冲之后都这样做——你可以等到一系列的结束,比如N 个脉冲。这意味着该设备可以使用相同的能量执行N 次乘法累加运算,以读取N是小还是大的答案。这里,N对应于神经网络中每层的神经元数量,很容易达到数千个。所以这个策略消耗的能量很少。
有时,您也可以在输入端节省能源。这是因为相同的值通常用作多个神经元的输入。与其将这个数字多次转换为光——每次都消耗能量——它可以只转换一次,产生的光束可以分成许多通道。通过这种方式,输入转换的能源成本可以在许多操作中分摊。
将一束光束分成多个通道不需要比透镜更复杂的事情,但将透镜放在芯片上可能很棘手。因此,我们正在开发的以光学方式执行神经网络计算的设备很可能最终成为一种混合体,它将高度集成的光子芯片与单独的光学元件结合在一起。
我在这里概述了我和我的同事一直在追求的策略,但还有其他方法可以破解optical cat。另一个很有前景的方案是基于一种叫做Mach-Zehnder 干涉仪的东西,它结合了两个分束器和两个全反射镜。它也可用于以光学方式进行矩阵乘法。两家麻省理工学院的初创公司Lightmatter和Lightelligence正在开发基于这种方法的光学神经网络加速器。Lightmatter 已经构建了一个原型,该原型使用其制造的光学芯片。该公司预计将在今年晚些时候开始销售使用该芯片的光加速器板。
另一家使用光学进行计算的初创公司是Optalysis,它希望复兴一个相当古老的概念。早在 1960 年代,光学计算的首批用途之一就是处理合成孔径雷达数据。挑战的一个关键部分是将称为傅立叶变换的数学运算应用于测量数据。当时的数字计算机一直在努力解决这些问题。即使是现在,将傅立叶变换应用于大量数据也可能是计算密集型的。但是傅立叶变换可以在光学上进行,只需要一个镜头,这就是多年来工程师处理合成孔径数据的方式。Optalysis 希望将这种方法更新并更广泛地应用。
还有一家名为Luminous的公司,是从普林斯顿大学分拆出来的,该公司正致力于创建基于激光神经元的尖峰神经网络。尖峰神经网络更接近地模仿生物神经网络的工作方式,并且像我们自己的大脑一样,能够使用很少的能量进行计算。Luminous 的硬件仍处于开发的早期阶段,但结合两种节能方法(尖峰和光学)的承诺非常令人兴奋。
当然,仍有许多技术挑战需要克服。一是提高模拟光学计算的精度和动态范围,这远不及数字电子设备所能达到的效果。这是因为这些光学处理器受到各种噪声源的影响,而且用于输入和输出数据的数模转换器和模数转换器精度有限。事实上,很难想象一个光学神经网络的运行精度超过 8 到 10 位。虽然存在 8 位电子深度学习硬件(Google TPU 就是一个很好的例子),但这个行业需要更高的精度,尤其是神经网络训练。
将光学元件集成到芯片上也存在困难。由于这些组件的尺寸为几十微米,它们无法像晶体管一样紧密地封装,因此所需的芯片面积会迅速增加。麻省理工学院研究人员在2017 年对这种方法的演示涉及一个边长为 1.5 毫米的芯片。即使是最大的芯片也不大于几平方厘米,这限制了可以通过这种方式并行处理的矩阵的大小。
光子学研究人员倾向于在计算机架构方面解决许多其他问题。但很清楚的是,至少在理论上,光子学有可能将深度学习加速几个数量级。
基于当前可用于各种组件(光调制器、检测器、放大器、模数转换器)的技术,可以合理地认为其神经网络计算的能源效率可以比当今的电子处理器高 1,000 倍. 对新兴光学技术做出更激进的假设,这个因素可能高达一百万。而且由于电子处理器功率有限,这些能源效率的改进很可能会转化为相应的速度改进。
模拟光学计算中的许多概念已有数十年历史。有些甚至早于硅计算机。光学矩阵乘法的方案,甚至是光学神经网络的方案,在 1970 年代首次得到证明。但这种方法并没有流行起来。这次会有所不同吗?可能,出于三个原因。
首先,深度学习现在真正有用,而不仅仅是学术上的好奇。其次,我们不能仅仅依靠摩尔定律来继续改进电子产品。最后,我们有了前几代人没有的新技术:集成光子学。这些因素表明,光神经网络这次将真正到来——而且这种计算的未来可能确实是光子的。
想想在不远的过去,计算机被应用到的许多任务需要人类的直觉。而现在计算机通常会识别图像中的物体、转录语音、在语言之间进行翻译、诊断医疗状况、玩复杂的游戏和驾驶汽车。
促成这些惊人发展的技术称为深度学习,这个术语指的是被称为人工神经网络的数学模型。深度学习是机器学习的一个子领域,是基于将复杂模型与数据拟合的计算机科学的一个分支。
虽然机器学习已经存在了很长时间,但深度学习最近开始了自己的新生命。其原因主要是因为越来越多的计算能力已经变得广泛可用——以及可以轻松收集并用于训练神经网络的大量数据。
在千禧年之际,人们触手可及的计算能力开始突飞猛进,当时图形处理单元 (GPU) 开始被用于非图形计算,这一趋势在过去十年中变得越来越普遍。但深度学习的计算需求增长得更快。这种动态促使工程师开发专门针对深度学习的电子硬件加速器,入谷歌的张量处理单元 (TPU)就是一个很好的例子。
在这里,我将描述解决这个问题的一种非常不同的方法——使用光学处理器,用光子而不是电子来执行神经网络计算。要了解光学如何在这里发挥作用,您需要对计算机目前如何进行神经网络计算有所了解。因此,当我概述引擎盖下发生的事情时,请耐心等待。
几乎无一例外,人工神经元是使用在某种数字电子计算机上运行的特殊软件构建的。该软件为给定的神经元提供多个输入和一个输出。每个神经元的状态取决于其输入的加权和(weighted sum),非线性函数(称为激活函数:activation function)应用于该输入。结果,这个神经元的输出,然后成为各种其他神经元的输入。
为了计算效率,这些神经元被分组到层中,神经元只连接到相邻层的神经元。与允许任何两个神经元之间的连接相反,以这种方式安排事物的好处在于它允许使用线性代数的某些数学技巧来加速计算。
虽然它们不是全部,但这些线性代数计算是深度学习中计算要求最高的部分,尤其是随着网络规模的增长。对于训练(确定将什么权重应用于每个神经元的输入的过程)和推理(当神经网络提供所需结果时)都是如此。
这些神秘的线性代数计算是什么?它们真的没有那么复杂。它们涉及对矩阵的操作,矩阵只是数字的矩形数组——电子表格,如果你愿意的话,减去你可能会在典型的 Excel 文件中找到的描述性列标题。
这是个好消息,因为现代计算机硬件已经针对矩阵运算进行了很好的优化,矩阵运算在深度学习流行之前很久就已经是高性能计算的基础。深度学习的相关矩阵计算归结为大量的乘法和累加运算,其中将成对的数字相乘并将它们的乘积相加。
多年来,深度学习需要越来越多的乘法累加运算。以LeNet 为例,这是一种开创性的深度神经网络,旨在进行图像分类。1998 年,它被证明在识别手写字母和数字方面优于其他机器技术。但到 2012 年推出的AlexNet,又是另一个神经网络,它的乘法累加运算次数是 LeNet 的 1600 倍,能够识别图像中数千种不同类型的对象。
从 LeNet 最初的成功发展到 AlexNet,需要将计算性能提高近 11 倍。在这 14 年的时间里,摩尔定律提供了大部分增长。现在的挑战是保持这种趋势,因为摩尔定律已经失去动力。通常的解决方案是在问题上投入更多的计算资源以及时间、金钱和精力。
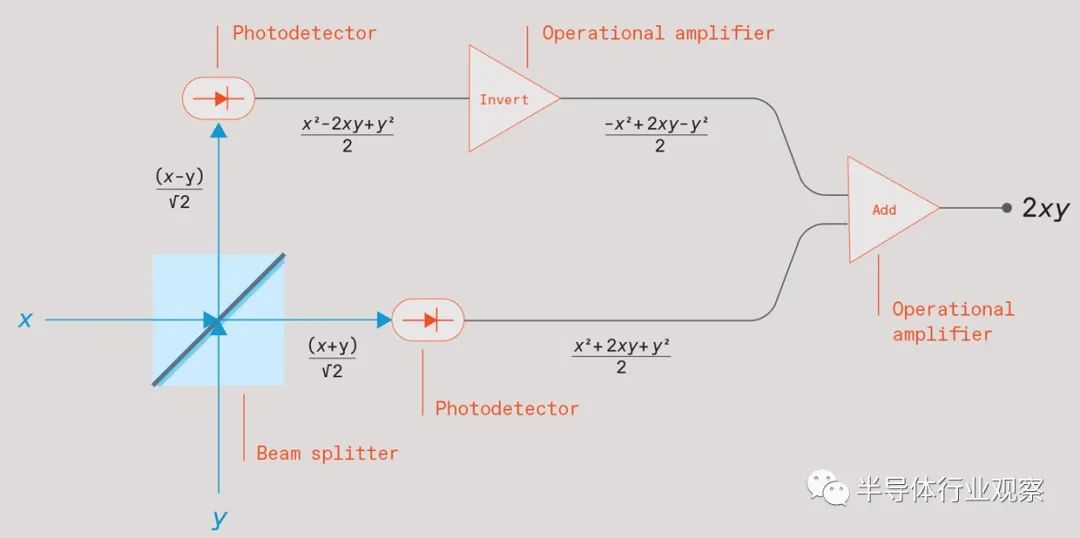
强度与要相乘的数字 x 和 y 成正比的两束光束撞击分束器 [蓝色方块]。离开分束器的光束照射在光电探测器 [椭圆形] 上,提供与光强度平方成正比的电信号. 将一个光电探测器信号反相并将其与另一个相加,就会产生一个与两个输入的乘积成正比的信号。
因此,训练当今的大型神经网络通常会产生显著的环境足迹。一个2019研究发现,例如,训练自然语言处理某深神经网络会产生一辆汽车终生驾驶所排放二氧化碳的五倍。
可以肯定的是,数字电子计算机的改进使深度学习得以蓬勃发展。但这并不意味着进行神经网络计算的唯一方法就是使用此类机器。几十年前,当数字计算机还相对原始时,一些工程师使用模拟计算机来解决困难的计算。随着数字电子技术的改进,那些模拟计算机被淘汰了。但现在可能是再次采用该策略的时候了,特别是当模拟计算可以通过光学方式完成时。
众所周知,光纤可以支持比电线高得多的数据速率。这就是为什么从 1970 年代后期开始,所有长途通信线路都采用光纤的原因。从那时起,光数据链路取代了铜线,跨度越来越短,一直到数据中心的机架到机架通信。光数据通信速度更快,功耗更低。光学计算承诺同样的优势。
但是通信数据和用它计算之间有很大的区别。这就是模拟光学方法遇到障碍的地方。传统计算机基于晶体管,晶体管是高度非线性的电路元件——这意味着它们的输出不仅与输入成正比,至少在用于计算时是这样。非线性是什么让晶体管打开和关闭,允许它们被塑造成逻辑门。这种切换很容易用电子设备来完成,因为电子设备的非线性非常重要。但是光子遵循麦克斯韦方程,这是令人讨厌的线性,这意味着光学设备的输出通常与其输入成正比。
解决问题的窍门是利用光学设备的线性来做深度学习最依赖的一件事:线性代数。
为了说明如何做到这一点,我将在这里描述一个光子设备,当它与一些简单的模拟电子设备耦合时,可以将两个矩阵相乘。这种乘法将一个矩阵的行与另一个矩阵的列组合在一起。更准确地说,它将这些行和列中的数对相乘,并将它们的乘积加在一起——我之前描述的乘法和累加运算。我和我的麻省理工学院同事发表了一篇关于如何在 2019 年做到这一点的论文。我们现在正在努力构建这样一个光学矩阵乘法器。
该设备中的基本计算单元是一个称为分束器(beam splitter)的光学元件。虽然它实际上可能更复杂,但你可以把它想象成一个 45 度角的半镀银镜子。如果你从侧面发射一束光,分束器会让一半的光直接穿过它,而另一半会从有角度的镜子反射,使它从入射光束以 90 度的角度反弹.
现在将第二束光垂直于第一束光照射到该分束器中,使其照射到成角度的镜子的另一侧。该第二光束的一半将类似地以 90 度角透射和反射。两个输出光束将与第一个光束的两个输出组合。所以这个分束器有两个输入和两个输出。
要使用此设备进行矩阵乘法,您需要生成两个光束,其电场强度与要相乘的两个数字成正比。我们称这些场强为x和y。将这两束光照射到分束器中,分束器将合并这两束光。这种特殊的分束器会产生两个输出,其电场值为 (x+y)/√2 和 (x−y)/√2。
除了分束器之外,这种模拟倍增器还需要两个简单的电子元件——光电探测器——来测量两个输出光束。不过,他们不测量这些光束的电场强度。他们测量光束的功率,该功率与其电场强度的平方成正比。
为什么这种关系很重要?要理解这一点,需要一些代数——但除了你在高中学到的知识之外,别无他物。回想一下,当你平方 (x+y)/√2 时,你会得到 (x²+2xy+y²)/2。当你平方 (x−y)/√2 时,你会得到 (x²−2xy+y²)/2。从前者中减去后者得到2xy。
现在停下来思考这个简单数学的重要性。这意味着如果你将一个数字编码为具有一定强度的光束,将另一个数字编码为另一种强度的光束,将它们发送通过这样的分束器,用光电探测器测量两个输出,并抵消产生的电信号之一在将它们相加之前,您将得到一个与两个数字的乘积成正比的信号。
Lightmatter 神经网络加速器中集成的 Mach-Zehnder 干涉仪的模拟显示了三种不同的条件,即在干涉仪的两个分支中传播的光经历不同的相对相移。
我的描述听起来好像这些光束中的每一个都必须保持稳定。事实上,您可以在两个输入光束中短暂地脉冲光并测量输出脉冲。更好的是,您可以将输出信号馈送到电容器中,然后只要脉冲持续,它就会积累电荷。然后您可以在相同的持续时间内再次脉冲输入,这次编码两个要相乘的新数字。他们的产品为电容器增加了一些电荷。您可以根据需要多次重复此过程,每次执行另一个乘法累加运算。
以这种方式使用脉冲光可以让您以快速的顺序执行许多此类操作。其中最耗能的部分是读取该电容器上的电压,这需要一个模数转换器。但是你不必在每个脉冲之后都这样做——你可以等到一系列的结束,比如N 个脉冲。这意味着该设备可以使用相同的能量执行N 次乘法累加运算,以读取N是小还是大的答案。这里,N对应于神经网络中每层的神经元数量,很容易达到数千个。所以这个策略消耗的能量很少。
有时,您也可以在输入端节省能源。这是因为相同的值通常用作多个神经元的输入。与其将这个数字多次转换为光——每次都消耗能量——它可以只转换一次,产生的光束可以分成许多通道。通过这种方式,输入转换的能源成本可以在许多操作中分摊。
将一束光束分成多个通道不需要比透镜更复杂的事情,但将透镜放在芯片上可能很棘手。因此,我们正在开发的以光学方式执行神经网络计算的设备很可能最终成为一种混合体,它将高度集成的光子芯片与单独的光学元件结合在一起。
我在这里概述了我和我的同事一直在追求的策略,但还有其他方法可以破解optical cat。另一个很有前景的方案是基于一种叫做Mach-Zehnder 干涉仪的东西,它结合了两个分束器和两个全反射镜。它也可用于以光学方式进行矩阵乘法。两家麻省理工学院的初创公司Lightmatter和Lightelligence正在开发基于这种方法的光学神经网络加速器。Lightmatter 已经构建了一个原型,该原型使用其制造的光学芯片。该公司预计将在今年晚些时候开始销售使用该芯片的光加速器板。
另一家使用光学进行计算的初创公司是Optalysis,它希望复兴一个相当古老的概念。早在 1960 年代,光学计算的首批用途之一就是处理合成孔径雷达数据。挑战的一个关键部分是将称为傅立叶变换的数学运算应用于测量数据。当时的数字计算机一直在努力解决这些问题。即使是现在,将傅立叶变换应用于大量数据也可能是计算密集型的。但是傅立叶变换可以在光学上进行,只需要一个镜头,这就是多年来工程师处理合成孔径数据的方式。Optalysis 希望将这种方法更新并更广泛地应用。
还有一家名为Luminous的公司,是从普林斯顿大学分拆出来的,该公司正致力于创建基于激光神经元的尖峰神经网络。尖峰神经网络更接近地模仿生物神经网络的工作方式,并且像我们自己的大脑一样,能够使用很少的能量进行计算。Luminous 的硬件仍处于开发的早期阶段,但结合两种节能方法(尖峰和光学)的承诺非常令人兴奋。
当然,仍有许多技术挑战需要克服。一是提高模拟光学计算的精度和动态范围,这远不及数字电子设备所能达到的效果。这是因为这些光学处理器受到各种噪声源的影响,而且用于输入和输出数据的数模转换器和模数转换器精度有限。事实上,很难想象一个光学神经网络的运行精度超过 8 到 10 位。虽然存在 8 位电子深度学习硬件(Google TPU 就是一个很好的例子),但这个行业需要更高的精度,尤其是神经网络训练。
将光学元件集成到芯片上也存在困难。由于这些组件的尺寸为几十微米,它们无法像晶体管一样紧密地封装,因此所需的芯片面积会迅速增加。麻省理工学院研究人员在2017 年对这种方法的演示涉及一个边长为 1.5 毫米的芯片。即使是最大的芯片也不大于几平方厘米,这限制了可以通过这种方式并行处理的矩阵的大小。
光子学研究人员倾向于在计算机架构方面解决许多其他问题。但很清楚的是,至少在理论上,光子学有可能将深度学习加速几个数量级。
基于当前可用于各种组件(光调制器、检测器、放大器、模数转换器)的技术,可以合理地认为其神经网络计算的能源效率可以比当今的电子处理器高 1,000 倍. 对新兴光学技术做出更激进的假设,这个因素可能高达一百万。而且由于电子处理器功率有限,这些能源效率的改进很可能会转化为相应的速度改进。
模拟光学计算中的许多概念已有数十年历史。有些甚至早于硅计算机。光学矩阵乘法的方案,甚至是光学神经网络的方案,在 1970 年代首次得到证明。但这种方法并没有流行起来。这次会有所不同吗?可能,出于三个原因。
首先,深度学习现在真正有用,而不仅仅是学术上的好奇。其次,我们不能仅仅依靠摩尔定律来继续改进电子产品。最后,我们有了前几代人没有的新技术:集成光子学。这些因素表明,光神经网络这次将真正到来——而且这种计算的未来可能确实是光子的。